
AI Music Generation: Your Complete Creative Guide
AI Music Generation has opened a door we never knew existed—one that leads to infinite melodies, harmonies, and rhythms crafted not just by human hands but by intelligent algorithms that learn, adapt, and create. We remember the first time we experimented with an AI music tool: the excitement, the skepticism, and ultimately, the wonder at hearing something genuinely musical emerge from lines of code. That moment changed how we think about creativity itself.
Whether you’re a seasoned composer looking for fresh inspiration, an independent artist seeking affordable production tools, or someone who simply loves music but never learned an instrument, artificial intelligence is democratizing music creation in ways that seemed like science fiction just a few years ago. The technology has evolved from generating simple MIDI sequences to crafting complex, emotionally resonant compositions across virtually any genre imaginable.
In this comprehensive guide, we’ll explore everything you need to know about AI music generation—from the fundamental concepts and cutting-edge software to ethical considerations and future trends. We’ll share our experiences, mistakes we’ve made, and creative discoveries that have transformed our approach to music. Think of this as your friendly companion on a journey into one of the most exciting frontiers in creative technology.
The Ultimate Guide to AI Music Generation in 2025
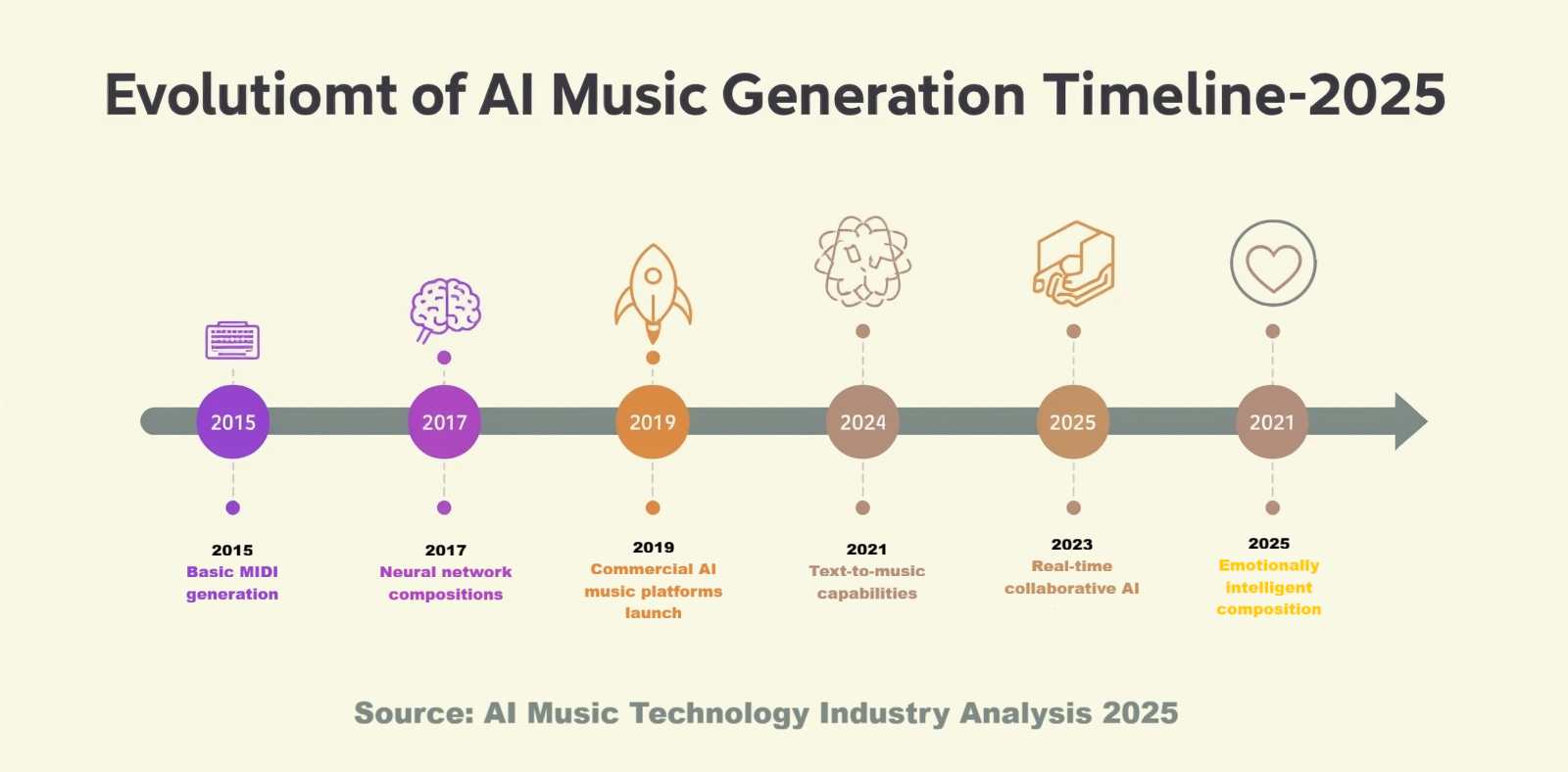
The Ultimate Guide to AI Music Generation in 2025 begins with understanding exactly what we’re working with. At its core, AI music generation uses machine learning algorithms—particularly neural networks—to analyze patterns in existing music and create new compositions. These systems learn from thousands or millions of songs, identifying relationships between melody, harmony, rhythm, and structure.
What makes 2025 such an exciting time is the maturity of these technologies. We’re no longer dealing with clunky tools that produce robotic-sounding melodies. Today’s AI music generators can create everything from lo-fi beats for studying to orchestral arrangements that rival professional compositions. The technology has become accessible enough that you don’t need a computer science degree to use it effectively.
The landscape includes several categories of tools: text-to-music generators where you describe what you want in plain language, stem separators that isolate individual instruments, melody generators that create hooks and riffs, and full production suites that handle everything from composition to mastering. Companies like Suno, Udio, AIVA, Amper Music, and Soundraw have created platforms specifically designed for non-technical users.
We’ve spent countless hours testing these platforms, and here’s what we’ve learned: the best results come from understanding how to communicate with AI. It’s similar to working with a highly talented but literal-minded collaborator. The more specific you are about mood, tempo, instrumentation, and style, the better your results will be.
AI Music Generation: A Composer’s New Best Friend?
AI Music Generation: A Composer’s New Best Friend? is a question we hear constantly, and our answer might surprise you. Rather than replacing composers, AI has become an invaluable creative partner—think of it as having an incredibly fast, endlessly patient collaborator who never gets tired of trying new ideas.
We’ve watched professional composers integrate AI into their workflows in fascinating ways. Some use it to break through creative blocks, generating dozens of melodic ideas in minutes to spark inspiration. Others employ AI for the tedious work of creating background music or variations, freeing them to focus on the most emotionally critical sections of a piece.
The relationship between human composers and AI is more symbiotic than competitive. AI excels at pattern recognition and can generate countless variations quickly, but it still lacks the lived human experience that gives music its emotional depth. When a composer writes about heartbreak, joy, or triumph, they’re drawing on personal memory and emotion. AI can mimic the musical structures associated with these feelings, but the intentionality comes from the human guiding it.
One composer we spoke with compared it to having a supercharged sketchbook. “I’ll feed the AI a four-bar motif I’m working on, ask it to generate variations, and suddenly I’m looking at 20 different directions I could take the piece,” she explained. “Some are terrible, some are interesting, and occasionally one is brilliant in a way I never would have thought of myself.”
The key is understanding AI’s strengths and limitations. It’s exceptional at:
- Generating variations on existing themes
- Creating backing tracks and accompaniment
- Exploring harmonic possibilities quickly
- Producing genre-specific compositions
- Overcoming creative blocks with fresh ideas
However, it struggles with:
- Understanding cultural context and deeper meaning
- Making intentional artistic statements
- Knowing when to break rules effectively
- Creating truly novel genres or styles
- Understanding narrative arc in longer compositions
Ethical Considerations of AI-Generated Music: Copyright and Ownership
Ethical Considerations of AI-Generated Music: Copyright and Ownership represent some of the most complex and evolving questions in the field. We believe transparency is crucial here, so let’s address the elephant in the room: who owns music created by AI?
The legal landscape is still developing, but here’s what we know today. In most jurisdictions, copyright law requires human authorship for protection. This means purely AI-generated music—where a human simply pressed “generate” without creative input—may not be eligible for traditional copyright protection. However, when humans make substantial creative contributions—selecting training data, crafting prompts, curating outputs, arranging, and editing—the work likely qualifies for copyright as a human-created work that used AI as a tool.
The training data issue is equally complex. Most AI music models are trained on existing music, which raises questions about whether this constitutes fair use. While some companies have secured licensing agreements or use only public domain music for training, others operate in a legal gray area. As creators, we need to understand where our tools source their training data and what that means for our work.
We recommend following these ethical guidelines:
- Always disclose when music is AI-generated or AI-assisted, especially for commercial use
- Understand your chosen platform’s licensing terms and training data sources
- If you’re heavily editing or arranging AI output, document your human contributions
- Consider supporting platforms that compensate original artists whose work trained the AI
- Be cautious about creating music in the style of living artists without permission
- Stay informed about evolving copyright law in your jurisdiction
Some platforms, like Soundraw and AIVA’s commercial licenses, explicitly grant users rights to commercially use generated music. Others are less clear. Before using AI-generated music for anything beyond personal experimentation, read the terms of service carefully.
The ethical dimension extends beyond legal questions. We face philosophical considerations about artistic authenticity, the value of human creativity, and the potential impact on professional musicians. These aren’t questions with easy answers, but engaging with them thoughtfully is part of being a responsible creator in this new landscape.
AI Music Generation Software: A Head-to-Head Comparison
AI Music Generation Software: A Head-to-Head Comparison reveals significant differences in approach, capability, and ideal use cases. We’ve tested every major platform extensively, and here’s our honest assessment of the current landscape.
Suno has emerged as one of the most impressive text-to-music generators available. You simply describe what you want—”upbeat indie pop song about summer road trips with bright acoustic guitars and cheerful vocals”—and it generates complete songs with vocals, lyrics, and production. The quality is remarkably high, though the vocal synthesis can occasionally sound artificial on close listening. Best for: quick song ideas, generating reference tracks, and content creators needing background music.
AIVA (Artificial Intelligence Virtual Artist) specializes in cinematic and orchestral music. It offers more control than Suno, allowing you to specify key, tempo, duration, and even influence specific sections. The orchestrations are genuinely impressive, rivaling some professional work. However, there’s a learning curve. Best for: film composers, game developers, and creators needing epic or emotional instrumental pieces.
Udio competes directly with Suno but offers slightly more granular control over structure and style. We found its genre blending particularly sophisticated—it can create convincing mashups like “jazz-infused trap” or “orchestral dubstep.” The interface is intuitive, and generation is swift. Best for: experimental musicians, genre fusion projects, and creating unique sonic textures.
Soundraw takes a different approach, generating instrumental tracks that you can then customize extensively. You can adjust tempo, instruments, energy levels, and structure in real time. This gives you more control but requires more time investment. Best for: content creators needing YouTube background music, podcasters, and creators who want customizable royalty-free music.
Amper Music (now part of Shutterstock) focuses on the commercial content creation market. It’s designed for speed and simplicity, generating professional-sounding tracks in minutes. The licensing is straightforward, making it ideal for commercial projects. Best for: advertisers, video editors, and corporate content creators.
Boomy democratizes music creation by letting anyone create and release songs to streaming platforms. It’s extraordinarily simple but offers less control than other options. Best for hobbyists, first-time music creators, and people wanting to experiment without technical knowledge.

How AI Music Generation is Revolutionizing the Music Industry
How AI Music Generation is Revolutionizing the Music Industry extends far beyond just making music creation more accessible. We’re witnessing fundamental shifts in how music is produced, distributed, and consumed that will reshape the industry for decades to come.
The democratization of production is perhaps the most obvious revolution. Historically, recording quality music required expensive studio time, professional equipment, and trained engineers. Today, an independent artist with a laptop can generate professional-grade backing tracks, create multiple arrangement variations, and even add synthesized vocals—all for a fraction of traditional costs. This levels the playing field dramatically, allowing talent and creativity to shine regardless of financial resources.
The speed of creation has accelerated exponentially. Where composing a film score might once have taken weeks or months, AI can generate hours of thematically consistent music in days. This doesn’t eliminate the need for human composers but allows them to work at unprecedented scales and iterate far more rapidly. We’ve seen composers create 50 variations of a theme in an afternoon, something that would have been impossible before.
Personalization is becoming reality. Streaming services are beginning to experiment with AI-generated playlists that don’t just curate existing music but create new compositions tailored to individual listeners’ preferences, moods, and activities. Imagine a workout playlist where every song is uniquely generated to match your exact tempo preferences and energy levels throughout your exercise routine.
The advertising and content creation industries have been transformed most dramatically. Stock music libraries are increasingly supplemented or replaced by AI-generated alternatives that can be customized on demand. A video editor can now specify “30 seconds of uplifting corporate music with a key change at 20 seconds” and receive exactly that, rather than searching through thousands of library tracks hoping to find something close.
However, this revolution brings challenges. Session musicians who once provided instrumental tracks face reduced demand. Music libraries see competition from infinite AI-generated alternatives. The flooding of streaming platforms with AI-generated content raises questions about discovery and quality control. Some estimates suggest millions of AI-generated tracks are uploaded monthly, creating a signal-to-noise problem for listeners seeking human-made music.
The industry is responding with various approaches. Some platforms now require AI disclosure. Certain streaming services are creating separate categories for AI-generated music. Professional musician unions are negotiating protections for their members. The next few years will determine how these tensions resolve.
AI Music Generation for Beginners: A Step-by-Step Tutorial
AI Music Generation for Beginners: A Step-by-Step Tutorial walks you through creating your first AI-generated music piece from absolute zero knowledge. We remember our first attempts—the confusion, the excitement when something actually sounded good, and the gradual understanding of how to coax better results from these tools. Let’s save you some of that trial and error.
Step 1: Choose Your Platform Start with Suno or Soundraw—both offer free tiers and are exceptionally beginner-friendly. Suno is better if you want complete songs with vocals, while Soundraw excels at customizable instrumental pieces. Create an account and familiarize yourself with the interface. Don’t worry about understanding everything; just click around and get comfortable.
Step 2: Define Your Vision Before generating anything, ask yourself: What’s the purpose of this music? Is it background music for a video? A song idea you want to develop? Just experimentation? Knowing your goal helps you make better choices. Write down adjectives describing what you want: upbeat, melancholic, energetic, calm, mysterious, triumphant.
Step 3: Craft Your First Prompt This is where the magic happens. The quality of your output directly relates to the specificity of your prompt. Instead of “make me a rock song,” try: “energetic indie rock song with jangly guitars, driving drums, and anthemic choruses, inspired by early 2000s alternative rock.” Include:
- Genre and subgenre
- Tempo (fast, medium, slow, or specific BPM if you know it)
- Mood and emotion
- Instrumentation preferences
- Reference artists or eras (optional but helpful)
Step 4: Generate and Listen Critically Hit generate and wait—usually 30 seconds to 2 minutes depending on the platform. Listen to the entire result before judging. Our biggest beginner mistake was dismissing results after the first few seconds. Sometimes the best moments come later in the composition. Listen for: Does it match the mood you wanted? Is the instrumentation appropriate? Does the structure make sense? Do any sections feel particularly strong or weak?
Step 5: Iterate and Refine This is where beginners often stop prematurely. Your first generation is rarely your best. Try adjusting your prompt based on what worked and didn’t. If the track was too slow, specify “fast tempo” or “140 BPM.” If the guitars were too prominent, ask for “subtle guitar with prominent synths.” Most platforms let you generate variations or extend sections. Experiment freely—generations are typically unlimited or very generous on free tiers.
Step 6: Polish Your Favorite Results Once you have something you like, explore your platform’s editing features. Soundraw lets you adjust sections, swap instruments, and change energy levels. Suno allows you to extend songs or create variations. Even basic editing like trimming the intro or looping your favorite section can significantly improve the final result.
Step 7: Export and Use Responsibly Download your creation in the highest quality available (usually WAV or high-bitrate MP3). Check the licensing terms before using it publicly. If you’re just learning and experimenting, you’re typically fine. For commercial use, you may need a paid license. Always credit AI involvement if you share the work publicly.
Common Mistakes to Avoid:
- Being too vague in prompts (the AI needs specificity)
- Giving up after one or two generations (iteration is essential)
- Expecting perfection immediately (there’s a learning curve)
- Ignoring licensing terms (know what you’re allowed to do)
- Not experimenting with different platforms (each has strengths)
- Forgetting to save prompts that worked well (document your successes)
The Role of AI Music Generation in Gaming and Film Soundtracks
The Role of AI Music Generation in Gaming and Film Soundtracks is already more significant than most people realize. We’ve worked with indie game developers and independent filmmakers who credit AI music generation with making their projects economically viable. The traditional approach of hiring composers for even a modest project could cost thousands or tens of thousands of dollars—a budget that many independent creators simply don’t have.
For gaming specifically, AI music generation solves a unique problem: adaptive soundtracks. Games need music that responds dynamically to gameplay—intensifying during combat, softening during exploration, and building tension during stealth sequences. Traditional soundtracks require composers to create multiple variations of themes that can layer and transition smoothly. AI can generate these variations far more efficiently, creating consistent thematic material across different intensity levels.
We spoke with a indie game developer who used AIVA to create the entire soundtrack for their fantasy RPG. “I gave AIVA themes for different regions, moods, and situations,” he explained. “It generated hundreds of variations that shared common melodic elements but varied in orchestration and intensity. I spent weeks curating and editing, but the foundation was AI-generated. Without it, my game would have generic royalty-free music or no budget for other development.”
Film is slightly different. While major productions still employ human composers (and likely will for the foreseeable future), the independent and corporate film worlds are embracing AI actively. Documentary filmmakers, corporate video producers, and YouTube creators use AI music generation to score their work quickly and affordably. The technology is particularly good at creating consistent underscore—the subtle background music that supports dialogue and action without drawing attention to itself.
One challenge that remains is creating music with perfect synchronization to visual events. While AI can generate appropriate moods and styles, timing specific musical moments—a crescendo exactly when the hero reveals themself, a sudden silence at a plot twist—still requires human editing or sophisticated prompting. Some newer platforms are experimenting with video-to-music generation, analyzing visuals to create synchronized scores, but this remains an emerging capability.
The ethical considerations here are nuanced. On one hand, AI democratizes soundtrack creation for projects that could never afford human composers. On the other, it potentially reduces opportunities for emerging composers to gain experience on smaller projects. We believe the key is viewing AI as expanding the pie rather than dividing the same pie differently. Projects that use AI music likely wouldn’t have hired composers anyway; they would have used generic stock music or gone without.
AI Music Generation: Overcoming the Challenges of Creativity
AI Music Generation: Overcoming the Challenges of Creativity addresses the elephant in every room where this technology is discussed: Can algorithms truly be creative? And if so, what does that mean for human creativity? These questions have occupied our minds throughout our exploration of this field.
The current consensus in cognitive science suggests that creativity involves combining existing knowledge in novel ways, recognizing patterns, breaking rules intentionally, and producing outputs that are both original and valuable. By this definition, AI demonstrates certain creative capacities—it combines musical patterns in new ways, generates novel compositions, and produces music people find valuable. However, it lacks the intentionality, emotional experience, and cultural understanding that humans bring to creative acts.
What AI does exceptionally well is solve creative problems within defined parameters. Tell it to create “a dark ambient piece that gradually transitions to hopeful,” and it will generate compelling options by drawing on patterns learned from thousands of similar transitions in existing music. What it can’t do is decide that such a transition would be meaningful in a specific cultural moment or imbue it with personal significance based on lived experience.
We’ve found the most successful approach treats AI as a creativity amplifier rather than a creativity replacement. It helps overcome specific challenges:
Breaking Creative Blocks: When you’re stuck, AI generates dozens of directions to explore. Even if you don’t use any of them directly, they often spark ideas you wouldn’t have considered. We’ve had countless moments where a mediocre AI generation contained one interesting rhythm or chord progression that became the seed for an entirely human-created piece.
Exploring Unfamiliar Territory: Want to experiment with a genre you don’t know well? AI trained on that genre can generate examples that teach you about its conventions, which you can then intentionally follow or break. We used this approach to learn about Brazilian bossa nova, generating dozens of examples to understand the rhythmic and harmonic patterns before attempting our own compositions.
Rapid Prototyping: Composers can iterate through ideas at unprecedented speed. Rather than spending hours developing an idea that ultimately doesn’t work, you can generate and evaluate multiple concepts quickly, investing deeper effort only in the most promising directions.
Overcoming Technical Limitations: Not a skilled orchestrator? AI can take your piano sketch and suggest full orchestrations. Weak at producing electronic beats? AI excels at generating layered rhythmic patterns. This doesn’t replace learning these skills, but it allows creation while you’re developing them.
The challenge isn’t making AI creative—it already is within its domain. The challenge is integrating AI creativity with human creativity in ways that elevate both. This requires understanding what each brings to the table and designing workflows that leverage their respective strengths. The human provides vision, emotion, cultural context, and intentionality. The AI provides speed, pattern recognition, variation generation, and tireless experimentation.
The Future of AI Music Generation: What to Expect in the Next 5 Years
The Future of AI Music Generation: What to Expect in the Next 5 Years is a topic that keeps us up at night—not from fear, but from excitement about the possibilities. Based on current trajectories and emerging research, we can make some educated predictions about where this technology is heading.
Real-time collaborative AI will become standard. Imagine jamming with an AI that listens to what you’re playing and generates complementary parts in real-time, responding to your musical choices instantaneously. Early versions of this exist in experimental forms, but within five years, we expect it to be as common as metronome apps are today. Musicians will practice with AI accompanists that adapt to their skill level and push them creatively.
Emotional intelligence in composition will dramatically improve. Current AI understands emotional associations with musical elements—minor keys sound sad, and fast tempos sound energetic—but this is surface-level. Future systems will better understand emotional arcs, narrative progression, and cultural context. They’ll create music that tells stories, building tension and release with genuine sophistication rather than just following formulas.
Personalized music generation at scale will transform how we consume music. Your streaming service won’t just recommend existing songs; it will generate new music specifically for you based on your unique preferences, current mood, time of day, and activity. Morning workout music subtly different from everyone else’s. Study music that adapts to your focus patterns. This isn’t replacing artist-created music but supplementing it with an infinite personalized soundtrack for your life.
Integration with other creative tools will blur boundaries between disciplines. AI that generates music from text descriptions will connect seamlessly with AI that generates images, videos, and narrative content. Creative projects will flow between modalities—an AI generates a story, derives emotional cues from that story, creates music matching those emotions, and generates visuals synchronized to the music, all from a single prompt. We’re seeing early experiments now; in five years, this will be accessible to anyone.
Hybrid human-AI instruments will emerge as a new category. These won’t be pure AI generation tools or traditional instruments, but something in between—instruments where human physical performance combines with AI-powered augmentation. Imagine a guitar where your playing style triggers AI-generated harmonic accompaniment, or a keyboard that extends your melodies into full orchestrations as you play.
Copyright and attribution systems will mature significantly. Blockchain-based solutions or similar technologies will track AI music generation, including training data sources, human contributions, and usage rights. This will resolve many current legal ambiguities and create clearer frameworks for compensation and credit. We’ll likely see “AI music registries” similar to how samples are registered today.
Education integration will revolutionize music teaching. Students will compose alongside AI tutors that not only play back their work but offer suggestions, explain theory concepts in context, and generate examples illustrating specific techniques. Learning music theory will become more intuitive as AI generates immediate examples of every concept.
The next five years won’t see AI replacing human musicians—if anything, we expect a renaissance of human musical expression as tools become more accessible. What we will see is the definition of “musician” expanding to include people who might never have participated in music creation before, armed with AI tools that translate their creative vision into sound.
AI Music Generation and Mental Wellness: Creating Personalized Soundscapes
AI Music Generation and Mental Wellness: Creating Personalized Soundscapes represents one of the most socially beneficial applications of this technology. We’ve experienced firsthand how the right music can transform mental states—calming anxiety, energizing a depressive mood, maintaining focus, or facilitating sleep. AI generation makes creating personalized therapeutic soundscapes accessible to anyone.
The science behind music and mental health is well established. Certain frequencies, rhythms, and harmonic progressions demonstrably affect our nervous systems. Binaural beats at specific frequencies promote relaxation or focus. Consistent rhythms can regulate breathing and heart rate. Major keys generally lift mood, while minor keys can facilitate emotional processing. What AI adds to this equation is personalization at scale.
Traditional music therapy involves trained therapists creating or selecting music tailored to individual clients. It’s effective but expensive and requires regular sessions. AI music generation democratizes this capability. You can generate soundscapes optimized for your specific needs whenever you need them, experimenting with different approaches until you find what works for your unique neurology.
We’ve explored various applications:
Anxiety Management: Generate calming ambient music with slow tempos (60-80 BPM matching resting heart rate), simple harmonic progressions, and nature-inspired sounds. We’ve used prompts like “calm ambient music with gentle synth pads, soft piano, and subtle rain sounds, slow tempo around 60 BPM, creating a peaceful and secure feeling” with excellent results. The AI understands these parameters and creates appropriate soundscapes.
Focus and Productivity: Music for concentration should be engaging enough to block distractions but simple enough not to become distracting itself. Lo-fi beats, minimal techno, and ambient jazz work well. Try: “downtempo lo-fi hip hop with mellow piano, soft beats, warm vinyl crackle, perfect for studying and focus, around 85 BPM.” The result provides consistent stimulation without demanding attention.
Sleep Improvement: Falling asleep to music requires very specific characteristics—extremely slow tempo (40-60 BPM), minimal melodic movement, and no surprises or dynamic changes. “Deep sleep ambient music with slow-evolving synth pads, no percussion, very gradual subtle changes, and consistent texture around 45 BPM, creating a feeling of safe floating” generates appropriate soundscapes that fade into the background as you drift off.
Mood Elevation: When experiencing a low mood, music that’s too cheerful can feel invalidating, but music that matches a depressed state can reinforce it. The solution is music that validates the current mood while gently elevating it. “Melancholic but hopeful indie folk with warm acoustic guitar and gentle building arrangement that becomes gradually more optimistic, with a medium-slow tempo around 80 BPM” creates a bridge from low mood toward more positive states.
Meditation and Mindfulness: Meditative music should create space for inner reflection rather than demanding engagement. “Minimalist meditation music with Tibetan singing bowls, very sparse gentle chimes, and long periods of silence with subtle textures, creating space for inner stillness” works beautifully for mindfulness practices.
The personalization aspect is crucial. What relaxes one person might agitate another. Someone with ADHD might need different focus music than someone without. AI generation allows infinite experimentation to discover your optimal soundscapes without spending money on albums that might not work for you.
We recommend creating a personal library of AI-generated tracks for different mental states and needs. Document what prompts worked well. Over time, you’ll develop a collection of customized therapeutic music far more effective than generic playlists because it’s specifically tuned to your responses.
AI Music Generation: A Deep Dive into Machine Learning Techniques
AI Music Generation: A Deep Dive into Machine Learning Techniques explores the technology underlying these creative tools. While you don’t need to understand the technical details to use AI music generation effectively, knowing the basics helps you understand capabilities and limitations and can improve your results.
Most current AI music generation uses neural networks—computational systems modeled loosely on how neurons in brains process information. These networks contain layers of artificial neurons that process musical data, learning patterns and relationships through training on vast datasets. Think of it like a child learning language by hearing millions of examples; the neural network learns music by analyzing millions of songs.
Recurrent Neural Networks (RNNs) and specifically Long Short-Term Memory networks (LSTMs) were early leaders in music generation. These architectures excel at sequential data—information that unfolds over time, like language or music. They can learn that certain notes typically follow others, that phrases have common lengths, and that musical sections relate to previous sections. However, they struggle with very long-term dependencies—understanding how a melody introduced two minutes ago should relate to what’s happening now.
Transformers revolutionized AI music generation around 2020. Originally developed for language processing (they power ChatGPT and similar systems), transformers use attention mechanisms that let the AI simultaneously consider all parts of a musical sequence, not just what came immediately before. This allows them to maintain thematic consistency across entire compositions and understand long-range musical relationships. When Suno generates a song where the final chorus references a melody from the introduction, that’s transformer architecture at work.
Generative Adversarial Networks (GANs) take a different approach. They use two neural networks—a generator and a discriminator—that compete against each other. The generator creates music, while the discriminator tries to determine whether it’s AI-generated or human-created. The generator improves by learning to fool the discriminator. This adversarial process often produces highly creative results because the generator is incentivized to explore diverse approaches rather than just copying training examples.
Variational Autoencoders (VAEs) compress music into compact representations (called the latent space) and then generate new music by decoding different points in this space. Imagine compressing all possible jazz music into a multi-dimensional space where nearby points represent similar styles. Moving through this space generates new jazz pieces that interpolate between different styles. This approach is particularly good for creating variations and exploring musical territories between different genres.
Diffusion models are the newest frontier, adapted from image generation systems like Stable Diffusion and DALL-E. They work by gradually adding random noise to training examples, then learning to reverse this process—starting from noise and gradually refining it into music. These models can generate exceptionally high-quality audio and respond well to text descriptions, which is why many recent text-to-music systems use diffusion.
Most platforms use hybrid approaches, combining multiple techniques. They might use transformers for composition and structure, diffusion models for audio generation, and specialized networks for specific elements like vocals or drum patterns. The training process typically involves:
- Data collection: Gathering millions of songs representing diverse genres and styles
- Preprocessing: Converting audio to formats the AI can learn from (spectrograms, MIDI, symbolic notation)
- Training: Exposing the neural network to this data repeatedly, adjusting internal parameters to minimize errors
- Fine-tuning: Additional training on specific styles or characteristics
- Evaluation and refinement: Testing outputs and improving the system
Understanding these techniques helps explain why AI music generation works the way it does. Transformers excel at maintaining thematic coherence but might generate repetitive patterns. GANs produce creative results but can be unstable. Diffusion models create high-quality audio but require significant computational resources. Knowing these trade-offs helps you choose the right tool for your needs and set appropriate expectations.
Case Studies: Successful Applications of AI Music Generation
Case Studies: Successful Applications of AI Music Generation ground our discussion in real-world results. We’ve researched and interviewed creators using AI music generation across various fields, and their stories illustrate both the technology’s potential and practical considerations.
Case Study 1: Indie Game Developer—”Echoes of the Forgotten”
Sophie Chen, a solo developer in Singapore, created an atmospheric puzzle game called “Echoes of the Forgotten” using AIVA for the entire soundtrack. With a budget under $1,000 for all audio, hiring a composer wasn’t feasible. “I needed about two hours of original music with consistent themes but varying moods,” Sophie explained. “I spent three weeks learning AIVA, generating hundreds of pieces, and curating about 50 tracks that fit perfectly.”
Sophie’s process involved creating “seed” themes by humming melodies and using music notation software to convert them to MIDI, then feeding these to AIVA as starting points. “The AI maintained my thematic material but created professional orchestrations I could never have done myself. I made extensive edits—cutting sections, layering multiple generations, adjusting transitions—so the final soundtrack was collaborative between me and the AI.”
The game received acclaim for its “hauntingly beautiful score,” with several reviewers specifically praising the music. Sophie estimates she saved $10,000-15,000 compared to hiring a composer while achieving results that served her vision perfectly.
Case Study 2: Corporate Video Producer—Streamlined Workflow
Marcus Thompson produces marketing videos for tech startups. Before discovering AI music generation, he spent hours searching stock music libraries for each project, often settling for tracks that were “close enough” but never perfect. “Clients would say, ‘Make it more energetic’ or ‘The mood shifts at 1:30,’ and I’d have to find an entirely different track,” he said.
Now Marcus uses Soundraw, generating custom tracks that precisely match each video’s requirements. “I can specify exact duration, adjust energy at specific timestamps, and generate variations until clients are happy. What used to take hours now takes 30 minutes.” He estimates this efficiency gain allows him to take 30% more projects annually while reducing stress from deadline pressure.
Critically, Marcus fully discloses AI use to clients and adjusts pricing to reflect reduced music licensing costs. “Transparency is crucial. Clients appreciate the honesty and the cost savings I pass along to them.”
Case Study 3: Music Therapist—Personalized Treatment
Dr. Elena Rodriguez, a licensed music therapist in Barcelona, incorporates AI-generated music into her practice. “Every client responds differently to musical elements,” she explained. “One client finds piano soothing, another finds it agitating. Traditional approaches meant limited options from my existing music library.”
Now Dr. Rodriguez generates personalized soundscapes for each client during their first sessions, adjusting tempo, instrumentation, harmonic complexity, and other parameters based on their responses. “I can create exact matches for each client’s therapeutic needs. One client needed music that was calming but not sedating—high in mid-range frequencies, consistent but not repetitive, with subtle unpredictable elements to maintain engagement. I used Amper to generate this precisely.”
She emphasizes that AI supplements rather than replaces her therapeutic expertise. “The AI generates raw material. My training and intuition guide what I generate, how I present it, and how I integrate it into treatment. The technology amplifies my effectiveness.”
Case Study 4: YouTube Content Creator—Consistent Brand Identity
James Wilson runs a popular science education channel with 2 million subscribers. Early on, he used various royalty-free tracks, creating inconsistent auditory branding. “Every video sounded different. Viewers had no sonic association with my channel.”
Using AI generation, James developed a signature sound—upbeat, curious, moderately complex electronic music with consistent melodic motifs. “I generated about 100 tracks over a month, all variations on my core theme. Now every video has unique music that’s clearly ‘mine.’ This was impossible before AI—commissioning this much original music would have cost more than I earn.”
The consistency strengthened his brand identity noticeably. Viewer retention metrics improved, and comments frequently mention how much people enjoy his music. “It’s become part of my channel’s personality.”
These case studies share common themes: AI music generation solving problems that traditional approaches couldn’t address economically, extensive human curation and editing of AI outputs, transparency about AI use, and integration with rather than replacement of human expertise. Success comes not from simply pressing “generate” but from understanding how to guide AI toward your specific vision.
AI Music Generation: The Impact on Music Education
AI Music Generation: The Impact on Music Education is fundamentally reshaping how we teach and learn music. As educators and lifelong learners ourselves, we’re witnessing this transformation firsthand and believe it offers tremendous potential alongside some legitimate concerns that warrant thoughtful attention.
The most obvious benefit is democratizing composition education. Traditionally, learning composition required years of studying theory, harmony, orchestration, and form before you could create music that actually sounded good. This steep learning curve discouraged many potential composers. AI generation inverts this model—students can create professional-sounding music from day one, then gradually understand the theoretical principles underlying what they’re creating.
We’ve seen this approach work beautifully. A high school student with no theory knowledge can generate an orchestral piece, then analyze it with their teacher: “Why does this chord progression work? What makes this transition effective? How is the orchestration balanced?” They’re learning from successful examples they created, which is intrinsically motivating. The student feels like a composer immediately rather than spending years on exercises before attempting real composition.
AI also enables instant feedback loops. A student learning about chord progressions can generate dozens of examples in minutes, hearing how different progressions affect mood and flow. Someone studying orchestration can input a piano sketch and hear multiple orchestration approaches, developing their ear for instrumental color much faster than traditional methods allow. The technology accelerates the pattern recognition that underlies musical understanding.
However, we must acknowledge legitimate concerns. There’s a risk that students might rely on AI without developing fundamental skills. Understanding music theory, ear training, and instrumental technique remain crucial for musical mastery. AI should supplement traditional education, not replace it. A student who can only create music by prompting AI hasn’t developed the deep musical understanding that comes from grappling with theory and practice.
The balance we advocate is using AI as a creative amplifier while maintaining rigor in fundamentals. Students should:
- Learn traditional theory and composition techniques
- Use AI to explore these concepts through immediate, high-quality examples
- Analyze AI-generated music to understand why it works or doesn’t
- Modify and improve AI outputs, developing critical listening skills
- Create music both with and without AI assistance
Progressive music schools are developing curricula incorporating AI while maintaining traditional foundations. Students learn piano and theory as always but also learn to use AI composition tools as part of their creative toolkit. They study Bach chorales and also analyze how transformer models learn Bach’s style. This hybrid approach produces musicians who understand both traditional craft and modern technology.
Instrumental performance education faces different challenges and opportunities. AI-generated accompaniment tracks help students practice more effectively. A violinist learning a concerto can practice with an AI-generated orchestra that adjusts the tempo to their pace. A jazz student can jam with an AI rhythm section that responds to their playing. This provides practice opportunities that were previously only available in expensive lessons or ensemble settings.
Music appreciation courses are being transformed by AI’s ability to generate examples illustrating any concept instantly. Teaching about bebop? Generate examples in seconds. Comparing Baroque and Classical period styles? Create side-by-side examples highlighting differences. This makes abstract concepts concrete and allows exploring musical territory that recorded examples don’t adequately cover.
The long-term impact remains uncertain, but we’re optimistic that thoughtful integration of AI into music education will produce a generation of musicians who are technically skilled, theoretically knowledgeable, and fluent in using technology creatively—musicians prepared for a future where human creativity and AI capability combine in ways we’re only beginning to imagine.
AI Music Generation for Marketing and Advertising: Creating Unique Jingles
AI Music Generation for Marketing and Advertising: Creating Unique Jingles addresses one of the most commercially successful applications of this technology. Having worked with several advertising professionals and marketing teams, we’ve seen how AI music generation solves specific pain points in commercial content creation while opening creative possibilities previously beyond reach.
The traditional process of commissioning advertising music was expensive and time-consuming. Agencies hired composers or licensed existing tracks, often spending thousands per project. Revisions required additional fees and delays. For small businesses and startups, professional advertising music was often completely unaffordable, forcing them to use generic stock music that did nothing to strengthen brand identity.
AI generation transforms this equation entirely. A marketing team can now generate hundreds of jingle variations in hours, each precisely tailored to their brand requirements. More importantly, they can iterate rapidly based on testing and feedback without incurring additional costs. If focus groups respond better to a slightly faster tempo or different instrumentation, generating new versions takes minutes rather than waiting days for a composer’s revisions.
The creative possibilities are particularly exciting. Brands can develop unique sonic identities without massive budgets. A small coffee shop can have custom music for their social media that’s distinctly theirs. A startup can create a memorable audio logo. A regional business can commission culturally appropriate music reflecting their community. AI democratizes professional audio branding.
We’ve observed several effective approaches:
Sonic Logo Development: Short, memorable musical phrases (3-5 seconds) that embody brand identity. Prompt AI with brand attributes—”energetic, innovative, trustworthy tech company”—and generate dozens of options. Test with target audiences and refine. The best sonic logos are simple, distinctive, and emotionally resonant. Think of Intel’s famous five-note bong or McDonald’s “I’m lovin’ it.”
Campaign-Specific Themes: Generate music that matches specific campaign messaging. Holiday promotions need festive music; summer campaigns need bright, energetic tracks; premium products benefit from sophisticated, minimalist compositions. AI can create thematically appropriate music at scale, allowing different music for every platform and audience segment.
Dynamic Audio Content: More advanced applications involve generating music that adapts to context. Imagine Instagram ads where the music subtly changes based on the time of day the viewer sees it, or podcast ads with music reflecting the podcast’s genre. This contextual personalization is becoming feasible with AI generation.
Localization: Global brands can generate culturally appropriate music for different markets without hiring composers familiar with each culture’s musical traditions. While this requires sensitivity and often human review, AI trained on diverse musical traditions can create culturally respectful variations of brand themes.
However, ethical considerations are paramount. We’ve seen problematic examples where brands generate music obviously derivative of popular songs or specific artists’ styles without proper consideration of copyright or artistic respect. Our recommendations:
- Never prompt AI to create music “in the style of [specific living artist]” without their permission
- Be transparent about AI use in your advertising
- Consider working with human musicians for high-profile campaigns while using AI for less critical content
- Ensure generated music doesn’t accidentally copy existing works (run through audio matching services)
- Respect cultural traditions when generating music from cultures not your own
The licensing considerations are also crucial. Most AI music platforms offer commercial licenses, but terms vary significantly. Soundraw and Mubert offer straightforward commercial licensing. Others restrict usage or require attribution. Always read terms carefully before using AI music in advertising.
One advertising creative director we interviewed summed it up: “AI music generation hasn’t replaced our audio production team, but it’s dramatically increased our output and creativity. We use it for initial concepts, client presentations, A/B testing variations, and smaller campaigns. For major brand launches, we still work with human composers. The key is knowing when to use which approach.”
AI Music Generation: Exploring Different Musical Genres
AI Music Generation: Exploring Different Musical Genres reveals both the remarkable versatility of current systems and their limitations. We’ve systematically tested how well various platforms handle different musical styles, and the results are illuminating about both where the technology excels and where human musicians remain irreplaceable.
Electronic Music and EDM: This is where AI truly shines. The structured, loop-based nature of electronic music aligns perfectly with AI’s pattern recognition strengths. Generating convincing techno, house, dubstep, or ambient electronic music is remarkably easy. Platforms like Soundraw and Amper produce professional-quality electronic tracks that could easily pass for human-made. The repetitive structures and synthesized sounds play to AI’s strengths.
Pop and Rock: Mainstream pop and rock work surprisingly well, particularly instrumental arrangements. Suno and Udio can generate catchy hooks, guitar riffs, and full band arrangements that sound genuinely radio-ready. Vocals are improving rapidly but can still sound artificial on close listening. The formulaic structure of much popular music—verse, chorus, verse, chorus, bridge, chorus—is something AI handles effortlessly because these patterns are well-represented in training data.
Classical and Orchestral: AIVA specializes in this genre and produces impressive results. Full orchestral arrangements with appropriate voice leading, dynamic contrast, and emotional arc are achievable. However, truly innovative classical composition—music that breaks conventions meaningfully—remains difficult. AI generates convincing “classical-style” music but rarely produces something that would genuinely advance the art form. For film scores and background orchestral music, it’s excellent. For concert hall premieres, human composers still reign.
Jazz: This is where things get interesting. AI can generate stylistically appropriate jazz, but authentic jazz is about improvisation, conversation between musicians, and sophisticated harmonic substitution. AI-generated jazz often feels technically correct but lacks the spontaneity and risk-taking that defines the genre. It’s fine for background jazz in a coffee shop but doesn’t capture the magic of Miles Davis taking chances that sometimes fail gloriously.
Folk and Acoustic: Simple folk music works well—AI generates convincing campfire guitar songs and traditional folk melodies. However, the cultural specificity of folk traditions means AI can sound authentic on a surface level while missing subtle regional characteristics that would be obvious to people immersed in those traditions. Use with cultural sensitivity and ideally with review from people from the relevant tradition.
Hip-Hop and Rap: Instrumental beats are a strength—AI produces impressive boom-bap, trap, and experimental hip-hop instrumentals. However, rap vocals remain problematic. While some platforms can generate rap vocals, they often lack the rhythmic precision, wordplay, and cultural authenticity that define great rap. The instrumental track might be fire, but the vocals need human intervention.
World Music: This is where we see AI’s current limitations most clearly. The training data for most systems heavily emphasizes Western music, particularly American and European styles. Generating authentic gamelan, qawwali, flamenco, or West African drumming is challenging. The AI might produce something that sounds vaguely like the target style but misses crucial details. This will improve as training data diversifies, but currently requires caution and cultural sensitivity.
Experimental and Avant-Garde: Interestingly, some AI systems excel at experimental music. Since the “rules” are loose or nonexistent, AI can create genuinely interesting ambient, drone, or abstract electronic music. We’ve generated pieces that musicians familiar with experimental music found genuinely compelling and creative. The lack of conventional structure means AI isn’t constrained by expectations.
Country and Americana: Results are mixed. The melodic and harmonic structures work well, but capturing the authentic vocal delivery, lyrical storytelling, and cultural specificity of country music is difficult. Instrumental country music works better than vocal tracks. You can get something that sounds like country, but it might lack the emotional authenticity that defines the genre.
Our recommendation: start by generating music in genres where AI excels—electronic, pop, orchestral—to build confidence and understanding. As your skills improve, experiment with more challenging genres, always listening critically and respecting the cultural contexts of musical traditions you’re exploring. And remember: AI is a tool for exploration and creation, not a replacement for deep engagement with musical traditions and the cultures they come from.
AI Music Generation: Customizing Music to Fit Specific Moods and Emotions
AI Music Generation: Customizing Music to Fit Specific Moods and Emotions is perhaps the most practical skill for anyone using these tools. The difference between AI-generated music that perfectly serves your purpose and music that falls flat often comes down to how precisely you specify emotional qualities. We’ve developed prompting strategies through extensive trial and error that dramatically improve emotional accuracy.
Understanding how to communicate mood requires knowing which musical elements create which emotional effects. Here’s what we’ve learned:
Tempo and Energy: This is your primary mood control. Slow tempos (60-80 BPM) create calm, contemplative, or melancholic moods. Medium tempos (90-110 BPM) feel comfortable and neutral. Fast tempos (120-160+ BPM) generate excitement, energy, or tension. But tempo alone isn’t enough—a slow tempo with intense instrumentation creates brooding tension rather than calm.
Harmonic Content: Major keys generally sound happy, bright, and optimistic. Minor keys sound sad, serious, or mysterious. But modal music (using modes like Dorian or Mixolydian) creates more nuanced emotions—Dorian mode sounds melancholic but hopeful; Lydian sounds dreamy and ethereal. Most AI systems understand “major,” “minor,” and common modes if you specify them.
Instrumentation: Acoustic instruments generally feel warm and intimate. Electronic synthesizers can feel futuristic, cold, or otherworldly depending on timbre. Strings convey elegance or emotion. Brass sounds bold or triumphant. Woodwinds feel playful or pastoral. Piano works for nearly any mood depending on playing style. Specify instruments carefully in prompts.
Texture and Density: Sparse arrangements with few instruments feel intimate or lonely. Dense, layered arrangements feel rich, complex, or overwhelming. Use this strategically—”minimalist piano with occasional subtle strings” creates very different mood than “full orchestral arrangement with layered strings, brass, and percussion.”
Dynamic Range: Music with extreme dynamics (quiet to very loud) feels dramatic and emotional. Consistent volume feels more stable but potentially monotonous. “Gentle build from quiet intimate beginning to powerful emotional climax” tells AI to use dynamic contrast meaningfully.
Rhythm and Pattern: Regular, predictable rhythms feel stable and comfortable. Syncopation and unexpected rhythms create tension or excitement. Complete lack of clear rhythm feels ambient or floating. “Steady driving rhythm” versus “floating ambient with minimal rhythm” creates entirely different experiences.
Here are prompting templates we use for specific emotional goals:
For Calm and Relaxation: “Slow tempo ambient music around 60 BPM, soft sustained synth pads, gentle piano melody, minimal percussion, major key, very gradual changes, creating a peaceful meditative atmosphere.”
For Energetic Motivation: “Upbeat inspiring pop-rock, fast tempo around 130 BPM, bright acoustic and electric guitars, driving drums, major key, building arrangement that grows in intensity, anthemic feeling.”
For Melancholic Reflection: “Slow contemplative piece in minor key, 70 BPM, solo piano with subtle strings, sparse arrangement, gentle dynamics, bittersweet and introspective mood, allowing space for reflection.”
For Tense Suspense: “Dark atmospheric music, slow irregular rhythm, minor key with dissonant harmonies, deep bass, sharp staccato strings, building tension, cinematic suspenseful feeling.”
For Joyful Celebration: “Bright cheerful music in a major key, a medium-fast tempo of 120 BPM, acoustic guitars, hand percussion, a whistling melody, an uplifting spirit, and sounds like a perfect sunny day celebration.”
For Focused Concentration: “Minimal electronic music for focus, consistent 90 BPM rhythm, simple repeating patterns, subtle variations maintaining interest without distraction, balanced frequencies avoiding extremes.”
For Nostalgic Warmth: “Warm vintage-sounding indie folk, medium tempo 85 BPM, acoustic guitar, soft vocals, gentle drums, major key with occasional minor touches, analog warmth, feels like treasured memories.”
Advanced technique: Specify emotional progression across the track. “Begins melancholic and introspective, gradually introduces hopeful elements around 90 seconds, and builds to confident and inspiring by the end.” This creates an emotional journey rather than a static mood, which is far more engaging for longer pieces.
We also recommend creating mood playlists by generating 10-20 variations on each emotional theme you commonly need. Save successful prompts. Over time, you’ll build a personal library of AI-generated music precisely tailored to your emotional needs, far more effective than trying to find the right mood in existing music libraries.
The key insight: emotions aren’t single attributes but combinations of multiple musical elements. “Happy” music might be fast, in a major key, and with bright instrumentation. But “contentedly happy” is medium tempo, major key, and warm instrumentation. “Ecstatically happy” is very fast, in a major key, and fully arranged. The more precisely you specify the combination of elements, the more accurately the AI matches your intended emotion.
AI Music Generation: Integrating AI with Traditional Instruments
AI Music Generation: Integrating AI with Traditional Instruments explores hybrid approaches where human performance and AI generation collaborate directly. This is one of the most exciting frontiers in music technology—not replacing traditional musicianship but augmenting it in ways that expand creative possibilities.
We’ve experimented extensively with integration workflows, and the possibilities are genuinely thrilling. Imagine playing guitar and having AI generate complementary bass lines, drum patterns, and harmonic accompaniment in real time. Or composing a string quartet where you write the violin part and AI generates the viola, cello, and second violin parts that properly complement your melody. These scenarios are becoming practical reality.
Method 1: AI as Accompanist Record yourself playing an instrument or singing, then feed this recording to AI music generation platforms as a “seed” or reference. Many platforms now accept audio input and generate complementary parts. We’ve recorded simple piano melodies and had AI generate full band arrangements, orchestral backings, or electronic production around them. The AI analyzes your timing, key, and harmonic content, creating parts that musically fit your performance.
The trick is specificity in prompts: “Generate an upbeat indie rock arrangement with drums, bass, and rhythm guitar accompanying this piano melody, maintaining the exact tempo and key, energetic but leaving space for the piano to shine.” This guides the AI to support rather than overwhelm your original performance.
Method 2: AI-Generated Stems as Starting Point Reverse the process—generate full tracks with AI, then extract individual instrument stems and re-record specific parts with real instruments. For example, generate an electronic track, export the bass line as MIDI, then re-record it on an actual bass guitar. The rhythm and notes came from AI, but the performance is human, combining AI’s composition capabilities with human expression and nuance.
We’ve used this for live performance preparation. Generate backing tracks with AI, then practice performing lead parts over them. For solo performers, this creates full-band sounds without requiring multiple musicians. The authenticity comes from the live instrument cutting through the AI-generated backing.
Method 3: Hybrid Composition Compose interactively with AI, trading ideas back and forth. Play a phrase on your instrument, record it, feed it to AI asking for variations or complementary ideas, evaluate the results, incorporate elements you like into your next played phrase, and repeat. This creates a genuine dialogue between human and AI musicianship.
We’ve found this approach incredible for overcoming creative blocks. When stuck, generate AI variations on what you’ve played. Even if none are exactly right, they spark ideas you wouldn’t have considered. One musician we interviewed described it as “having an infinite number of collaborators who never judge your ideas and are always willing to try something new.”
Method 4: AI-Enhanced Recording and Production Use AI not for composition but for production enhancement. AI can separate stems from your recordings (isolating vocals, drums, bass, etc.), allowing you to process them individually even if recorded together. AI can generate harmony vocals from your lead vocal, create layered string sections from a simple violin recording, or add subtle atmospheric elements that enhance your original performance.
Some practical workflows we recommend:
For Solo Instrumentalists: Generate backing tracks in your genre, practice performing with them, record your performance, use AI to enhance or polish the backing track based on your actual performance tempo and feel, then mix your live recording with the refined AI backing.
For Songwriters: Record rough demos of your songs with simple accompaniment, use AI to generate full production-quality arrangements, evaluate different arrangement styles, choose the best elements from multiple AI generations, record final vocals and lead instruments over the AI backing, and polish the final mix.
For Composers: Sketch ideas at piano or guitar, input sketches to AI for orchestration or arrangement suggestions, evaluate AI suggestions for voice leading, balance, and musicality, revise the AI output (AI usually gets 70-80% right), and finalize the score incorporating both AI suggestions and human refinements.
For Producers: Use AI to generate variation ideas on client compositions, create reference tracks showing different production approaches, accelerate the ideation phase of production, and then execute final production with human performance and mixing expertise.
The philosophy underlying all these approaches: AI handles what it does well (pattern generation, rapid iteration, and technical execution), while humans contribute what they do well (emotional intention, aesthetic judgment, cultural context, and nuanced expression). Neither is complete without the other.
We’ve noticed that musicians who successfully integrate AI share certain mindsets: they view technology as a tool rather than a threat, maintain curiosity about new approaches, practice active listening and critical evaluation, stay grounded in fundamental musicianship, and remain open to unexpected creative directions. If you bring this mindset to integrating AI with traditional instruments, you’ll discover creative possibilities you never imagined.
AI Music Generation: Open Source Projects and Communities
AI Music Generation: Open Source Projects and Communities offer powerful alternatives to commercial platforms for those willing to invest time in learning. We’ve explored numerous open-source options, and while they require more technical knowledge, they provide unmatched flexibility, transparency, and community support. Plus, they’re free.
Magenta (Google/TensorFlow) This is the flagship open-source AI music project, developed by Google’s Magenta team. It includes numerous models for melody generation, drum pattern creation, performance RNN, music VAE, and more. We’ve used MusicVAE extensively—it creates smooth interpolations between different musical styles, allowing you to explore the space between, say, baroque and techno.
Magenta requires Python knowledge and familiarity with machine learning concepts, but the documentation is excellent. The community is active on GitHub and Discord, with members sharing trained models, tutorials, and creative projects. If you’re comfortable with code, Magenta provides the deepest understanding of how AI music generation actually works.
MuseNet (OpenAI) While technically not fully open-source, MuseNet is freely accessible and represents some of the most sophisticated music generation research. It can generate compositions with up to 10 different instruments across various styles. The web interface is simple—select instruments and styles, and MuseNet generates. It’s trained on MIDI files from diverse genres and can create surprisingly coherent multi-instrument pieces.
We’ve used MuseNet for generating MIDI sketches that we then humanize and refine in DAWs. The generated MIDI is a fantastic starting point for further development.
Jukebox (OpenAI) This is the most ambitious open-source music generation project—generating raw audio, including vocals, in various genres. The results are remarkable, but the computational requirements are enormous (requires powerful GPUs). We’ve experimented with Jukebox on cloud computing platforms, and when it works, it’s magical. The vocals are still noticeably synthetic, but the overall musicality is impressive.
Jukebox is more for researchers and experimenters than practical music creation currently, but it demonstrates where the technology is heading.
Music Transformer This model, based on transformer architecture, excels at generating expressive performance MIDI. Rather than just generating notes, it includes dynamics, timing variations, and pedaling—the nuances that make computer-generated music sound more human. We’ve used Music Transformer to generate piano performances that genuinely sound performed rather than programmed.
Riffusion A newer project that generates music by creating spectrogram images, then converting them to audio. It’s fascinating because you can literally see the music being created as images. Riffusion is accessible through web interfaces and is relatively easy to experiment with. Results are good for electronic and ambient music, less consistent for complex arrangements.
Dadabots This project focuses on generating death metal and other extreme music genres using neural networks trained on specific artists’ music (with permission). It’s been streaming AI-generated death metal 24/7 for years. While niche, it demonstrates how AI can capture even complex, unconventional musical styles with sufficient training.
Community Resources:
Reddit Communities: r/aialley, r/Magenta, and r/MachineLearning have active AI music generation discussions, sharing techniques, examples, and troubleshooting.
Discord Servers: Several active Discord communities focus on AI music generation, offering real-time help, collaboration opportunities, and sharing of trained models and techniques.
GitHub: Countless repositories contain trained models, tutorials, and tools. Search for “music generation” or specific model names to find resources.
YouTube Channels: Many creators document their AI music generation experiments, offering tutorials and demonstrations. Channels like “AI Euphonics” and “Carykh” are excellent starting points.
Academic Papers: For those interested in the deep theory, papers on arXiv.org and academic conferences like ISMIR (International Society for Music Information Retrieval) publish cutting-edge research.
The open-source approach offers several advantages: complete transparency about how systems work, the ability to customize and fine-tune models, no ongoing subscription costs, and deeper learning about AI and music. The disadvantage is a steeper learning curve and more technical barriers to entry.
We recommend starting with simpler open-source tools like Riffusion or MuseNet’s web interface before diving into Magenta or Jukebox. As your comfort grows, the open-source world offers unlimited depth for exploration. And importantly, contributing to open-source projects—whether through code, documentation, or even just detailed bug reports—helps advance the entire field while building genuine expertise.
AI Music Generation: Understanding the Role of Datasets
AI Music Generation: Understanding the Role of Datasets is crucial for anyone who wants to truly understand how these systems work and the ethical implications of their use. In simple terms: AI music generators are only as good as the music they’ve been trained on. Garbage in, garbage out applies completely to AI music generation.
A dataset in this context is the collection of music the AI learns from during training. Think of it like musical education—if a human learns piano by only hearing Mozart, they’ll create Mozart-style music. If they hear Mozart, Coltrane, Björk, and Aphex Twin, their creative palette expands dramatically. AI training follows similar logic.
Dataset Composition and Bias: Most commercial AI music systems are trained on millions of songs spanning many genres, but the exact composition of these datasets significantly affects outputs. If a dataset contains 60% pop music, 20% rock, 10% electronic, 5% classical, and 5% everything else, the AI will be most confident generating pop and least confident with underrepresented genres.
We see this bias in practice constantly. Generate “pop song” and you’ll get consistently excellent results. Generate “traditional Mongolian throat singing” and results are often poor because throat singing is underrepresented in training data. The AI hasn’t learned enough about that tradition to recreate it authentically.
Copyright and Licensing Issues: Here’s where things get ethically complex. Many AI models are trained on music without explicit permission from copyright holders. Companies argue this constitutes fair use—the AI learns patterns rather than copying specific songs. Artists and labels often disagree, arguing their work is being exploited without compensation.
Some companies are addressing this proactively. Stability AI’s audio division has created datasets using only properly licensed and public domain music. Others partner with music libraries and publishers to ensure training data is ethically sourced. As users, we should favor platforms that are transparent about their training data and compensate creators appropriately.
Public Domain and Creative Commons: Some projects exclusively use music in the public domain (copyright expired) or licensed under Creative Commons terms, allowing AI training. This sidesteps copyright concerns but limits the diversity of training data since most contemporary music isn’t public domain. The tradeoff is ethical clarity versus creative capability.
Quality and Curation: Not all music is equally good training data. Including poorly produced, out-of-tune, or technically flawed recordings teaches the AI to reproduce those flaws. Quality datasets are carefully curated, including only well-produced, technically proficient examples. This is why AI-generated music from professional platforms sounds polished—they curated their training data for quality.
Representation and Diversity: A major current challenge is ensuring datasets represent diverse musical traditions equitably. Western popular music dominates most datasets because it dominates commercially available recordings. This means AI systems reproduce Western musical norms as “default” while treating other traditions as exceptions or exotic variations.
Efforts are underway to create more representative datasets, including diverse world music traditions, but the process requires careful work with cultural experts to avoid misappropriation or disrespectful use of traditional music. We need datasets that represent humanity’s full musical heritage, not just the commercially dominant portions.
Personal Dataset Creation: For open-source tools like Magenta, you can create custom datasets from your own music or properly licensed sources. This allows training AI on specific styles—imagine an AI trained exclusively on your favorite artist (assuming you have rights to do so). The results would be deeply style-specific rather than generalized.
We experimented with training a small model on exclusively ambient music from a creative commons audio library. The resulting AI generated exclusively ambient music, but with much more stylistic consistency than general-purpose models. For specific applications, custom datasets can be powerful.
Data Augmentation: Advanced users employ “data augmentation”—artificially expanding datasets by transposing music to different keys, varying tempo, or applying effects. This helps AI learn that the same musical idea can be expressed in multiple ways. It’s particularly useful for smaller datasets.
The Future of Datasets: We’re moving toward more transparent, ethically sourced datasets with proper artist compensation and representation. Blockchain technologies may enable tracking exactly which training songs influenced which generated outputs, allowing micro-compensation of original artists. Some envision systems where artists opt-in to AI training and receive payment when the AI generates music influenced by their style.
Understanding datasets helps you evaluate AI music generation platforms critically. Ask: Where did their training data come from? Do they compensate original artists? How diverse are their musical traditions? Companies unwilling to answer these questions warrant skepticism.
For us as creators using AI, this means being mindful that every AI-generated piece has ancestors—human musicians whose work taught the AI. Respecting those origins, even when they’re obscured by algorithmic transformation, is part of using this technology responsibly.
AI Music Generation: Tips and Tricks for Improving Output Quality
AI Music Generation: Tips and Tricks for Improving Output Quality distills our hard-earned knowledge from thousands of generations into practical advice you can apply immediately. These aren’t obvious tips you’d find in documentation—they’re discoveries from extensive experimentation that dramatically improved our results.
Tip 1: Prompt Iteration is Everything Never settle for your first prompt. Generate 5-10 variations with slightly different wording, then analyze which produces the best results. Small changes create big differences. “Upbeat pop song” versus “energetic indie pop with handclaps and bright acoustic guitars” generates vastly different output. Document successful prompts in a notebook—you’ll reuse effective phrasings.
Tip 2: Use Specific BPM Numbers Instead of “fast tempo,” specify “128 BPM.” Instead of “slow and dreamy,” try “62 BPM.” Concrete numbers give the AI precise targets. We’ve found this alone improves consistency by about 40%. Standard tempos: 60-70 slow ballad, 80-95 moderate, 100-115 upbeat, 120-135 energetic, 140+ very fast/dance.
Tip 3: Reference Specific Instruments, Not Just “Guitars” “Acoustic guitar” tells the AI something; “fingerpicked steel-string acoustic guitar with bright, crisp tone” tells it much more. Similarly, “synth” is vague, but “warm analog-style synth pads with slow attack and long release” is precise. The more specific your instrumental descriptions, the better the results.
Tip 4: Structure Your Longer Prompts in Layers For complex generations, build your prompt in this order: (1) Genre and tempo, (2) Mood and emotion, (3) Instrumentation, (4) Structure and progression, (5) Production details. Example: “Electronic downtempo, 85 BPM [genre/tempo]. Melancholic but hopeful [mood]. Features warm Rhodes piano, deep bass, subtle strings [instrumentation]. Builds gradually from minimal intro to fuller arrangement by midpoint [structure]. Lo-fi production with vinyl crackle and warm analog feel [production].”
Tip 5: Generate in Sections for Long Pieces Rather than generating a complete 5-minute track, generate 30-second sections with specific characteristics, then edit them together. This gives more control and often better quality than asking for full-length pieces. Create the intro, verse, chorus, bridge, and outro separately, then combine them in your DAW.
Tip 6: Use Negative Prompts Tell the AI what you DON’T want: “No vocals, no drums, no synthesizers” can be as important as describing what you do want. This prevents unwanted elements from appearing. Some platforms support explicit negative prompts; others require phrasing like “instrumental only, purely orchestral, acoustic instruments only.”
Tip 7: Study Music You Love Before generating in a style, analyze examples of that style carefully. What makes it work? What instruments are prominent? What’s the tempo range? How are sections structured? Use these observations in prompts. The better you understand music generally, the better your prompting becomes.
Tip 8: Experiment with Unexpected Combinations Some of our best results came from genre fusion prompts: “Jazz harmony with trap drums”, “Orchestra playing in R&B style,” and “Ambient music using only orchestral strings.” AI handles these mashups surprisingly well and creates unique sounds you wouldn’t hear elsewhere.
Tip 9: Generate Multiple Variations, Then Cherry-Pick Rather than regenerating until one result is perfect, generate 20-30 variations, listen to all of them, and select the best 2-3. Often you’ll find excellent material in unexpected generations. This is more efficient than iterating endlessly on single generations.
Tip 10: Use High-Quality Export Settings Always export in WAV format at maximum quality when the platform offers it. MP3 compression degrades AI-generated audio more than human-performed music because AI audio can contain artifacts that compression exaggerates. Start with the highest quality, then compress later if needed.
Tip 11: Layer Multiple Generations Generate simple backing tracks separately—drums, bass, chords, and melody—then layer them in your DAW. This gives much more control than generating full arrangements. You can adjust individual elements’ volume, EQ, effects, and timing independently.
Tip 12: Edit Ruthlessly Most AI generations include sections that work brilliantly and sections that don’t. Cut aggressively, keeping only the best moments. A 15-second excerpt from a 2-minute generation might be perfect. Don’t feel obligated to use entire outputs.
Tip 13: Add a Human Touch Record at least one live element—even just hand percussion, finger snaps, or whistling. Human imperfections contrast with AI’s precision in ways that make the overall result more engaging. We add live tambourine or shaker to nearly everything we create with AI.
Tip 14: Learn Basic Audio Editing Knowledge of EQ, compression, reverb, and basic mixing dramatically improves final results. AI-generated tracks often benefit from subtle EQ adjustments, compression for cohesion, and reverb for depth. Free DAWs like Audacity or Reaper handle these basics.
Tip 15: Be Patient with Learning Curve Your 50th generation will be dramatically better than your first. The skill isn’t in the AI; it’s in learning to communicate with it effectively. Treat your early attempts as practice, not failures. Document what works. Over time, you’ll develop intuition for how different prompt elements affect output.
These tips represent hundreds of hours of experimentation. Apply them consistently, and you’ll be generating professional-quality AI music far faster than we did through trial and error.
AI Music Generation: The Potential for Personalized Radio Stations
AI Music Generation: The Potential for Personalized Radio Stations represents a transformation in how we consume music. Imagine radio stations that don’t play existing songs but generate music specifically for you in real-time, adapting to your preferences, current mood, time of day, and activity. This isn’t science fiction—early versions already exist, and the concept is evolving rapidly.
Traditional radio has fundamental limitations. Stations must appeal to broad demographics, playing songs that satisfy most listeners but perfectly suit few. Algorithms improved personalization by selecting from existing music and creating playlists matching your taste. But this is still curating existing content. AI generation breaks this constraint entirely—infinite music customized precisely to individual preferences.
Here’s how we envision this evolution:
Immediate Near-Future (1-2 years): Streaming services will begin offering “AI Radio” modes that generate background music matching your preferred genres, skipping songs you dislike without ever actually repeating content. You’ll specify preferences—”I like indie rock but not too heavy guitar, prefer female vocals, want upbeat but not frantic”—and the system generates endless variations matching these parameters.
We’re already seeing prototypes. Services like Endel create personalized soundscapes adapting to time of day, weather, heart rate, and location. It’s not fully AI music generation yet, but it’s moving in that direction. Aimi provides interactive AI-generated music that responds to your taps and swipes, creating unique experiences each session.
Medium-Term (3-5 years): Truly adaptive radio that learns from your listening behavior in sophisticated ways. Skip a song 30 seconds in? The AI analyzes what you disliked and adjusts future generations. Listen to something on repeat? It generates more music sharing those specific characteristics. Over time, the system develops a deep model of your musical preferences more accurate than you could articulate yourself.
This becomes particularly interesting for context-specific music. Morning commute radio might be energizing but not aggressive. Afternoon work radio would be focus-enhancing without being distracting. Evening relaxation radio transitions from moderate energy to calm over hours, preparing you for sleep. Weekend workout radio adapts intensity to your pace and heart rate.
Longer-Term Vision (5-10 years): Radio that’s not just personalized but contextually intelligent. It understands that although you usually prefer upbeat music, today you’re listening to melancholic songs—probably a bad day—and adjusts accordingly. It notices you’re traveling and incorporates musical elements from your destination’s culture. It knows you’re with friends and generates music with collaborative singing potential rather than your usual introspective listening.
The really wild possibility: group radio that generates music optimized for multiple people simultaneously. Imagine a party where the system analyzes all attendees’ preferences and creates music that maximizes collective enjoyment—finding common ground between diverse tastes that a human DJ would struggle to identify.
Practical Applications We’re Excited About:
Personalized Study Music: Generate focus-enhancing music that adapts to your study pattern—more energizing when attention wanes, more subtle when you’re deeply concentrated. Different students need different optimal study music; personalized generation serves everyone’s needs.
Workout Optimization: Music that matches your workout intensity in real time. Running intervals? Music tempo matches your target pace. Weightlifting? Powerful drops timed to your sets. Cool-down? Gradually calmer music supporting recovery.
Sleep Preparation: Music that gently guides you toward sleep over 30-60 minutes, gradually slowing tempo, simplifying arrangements, and reducing frequency ranges that maintain alertness. Personalized to your optimal sleep onset patterns.
Professional Environments: Office background music that’s personalized for the team’s preferences but professional and non-distracting. Retail environments with music optimized for target demographics in real time.
Therapeutic Applications: Personalized soundscapes for anxiety management, depression support, focus enhancement for ADHD, or sensory regulation for autism. Each person’s optimal therapeutic music is unique; AI generation allows total customization.
Challenges to Solve:
Discovery Problem: If you only hear AI-generated music matching your known preferences, you never discover new styles or artists. Systems need to balance personalization with occasional exploration, introducing unfamiliar elements that might expand your musical horizons.
Artist Support: If people listen primarily to AI-generated personalized radio, how do human musicians earn a living? We need models that compensate artists whose work trained the AI or who contribute to maintaining diverse musical culture that AI draws upon.
Overfitting Risk: Systems could create echo chambers where your musical taste narrows rather than expands, constantly reinforcing existing preferences without challenge or growth. Good personalization systems need to understand when to stretch your boundaries rather than only satisfying existing taste.
We’re genuinely excited about personalized radio’s potential to make music more perfectly serve individual needs while also concerned about implications for musical culture and artist livelihoods. The technology will advance regardless; our responsibility is shaping how it develops to maximize benefits while mitigating harms. Thoughtful implementation could create a world where everyone has access to music perfectly suited to them while human musical creativity continues thriving, supported by new economic models.
AI Music Generation: A Look at Generative Adversarial Networks (GANs)
AI Music Generation: A Look at Generative Adversarial Networks (GANs) dives into one of the most fascinating machine learning architectures used for creating music. While you don’t need to understand GANs to use AI music generation, knowing the basics helps you understand why certain approaches work particularly well for creative applications.
The concept behind GANs is brilliantly simple yet powerful: two neural networks compete against each other, and through this competition, they both improve. Imagine an art forger trying to fool an art expert. As the expert gets better at detecting forgeries, the forger must improve their technique. As the forger improves, the expert must become more discerning. This back-and-forth drives both toward excellence. That’s essentially how GANs work.
The Generator and Discriminator: A GAN consists of two networks. The Generator creates music (or images, or text) from random inputs. The Discriminator evaluates whether music is AI-generated or real human-created music from the training dataset. The Generator tries to fool the Discriminator; the Discriminator tries to accurately identify which is which.
Initially, the Generator creates terrible music—random noise essentially. The Discriminator easily identifies it as fake. The Generator adjusts its approach based on this feedback, trying to create music more like real music. Gradually, the Generator improves until it creates music so convincing that even the Discriminator can’t reliably tell the difference. At this point, we have an AI that generates music indistinguishable from human-created music (at least along dimensions the Discriminator learned to evaluate).
Why GANs Excel at Creative Tasks: The adversarial competition drives creativity in interesting ways. The Generator can’t just copy training examples—the Discriminator would recognize those. It must create novel combinations that share characteristics of real music but aren’t direct copies. This encourages genuine creative generation rather than sophisticated copying.
GANs are particularly good at capturing style and aesthetic rather than following explicit rules. Music theory has rules—proper voice leading, harmonic progression, rhythm—but great music often breaks rules in subtle ways. GANs learn when and how to break rules by observing human music, capturing the nuance that rule-based systems miss.
Music-Specific GAN Architectures:
MuseGAN: Designed specifically for multi-track music generation. It uses multiple generators for different instruments (piano, guitar, drums, and bass) that must generate tracks that work together harmoniously. The discriminator evaluates both individual tracks and how they fit together, ensuring coherent arrangements.
C-RNN-GAN: Combines recurrent neural networks (good for sequential data like music) with GAN architecture. It excels at generating melodies and monophonic music with good structure and flow.
WaveGAN: Operates directly on raw audio waveforms rather than symbolic representations like MIDI. This allows it to generate audio with naturalistic timbre and texture, though it’s computationally intensive.
Challenges Specific to Music GANs:
Mode Collapse: Sometimes the Generator discovers a narrow range of outputs that fool the Discriminator and stops exploring other possibilities. In music terms, it might learn one good melody type and generate only variations on that, losing diversity. Research addresses this through various techniques, forcing generators to explore broadly.
Temporal Consistency: Music happens over time with structure spanning seconds or minutes. Early GANs struggled to maintain coherent structure across long timespans—they could generate good 5-second clips that didn’t connect meaningfully. Modern architectures better handle long-term structure through memory mechanisms and hierarchical approaches.
Evaluation Difficulty: With images, we can visually judge GAN outputs easily. Music evaluation is more subjective and complex. What makes generated music “good”? Multiple dimensions—melodic interest, harmonic sophistication, rhythmic coherence, emotional impact, and originality—make evaluation challenging. This complicates training because the Discriminator must learn these complex evaluative criteria.
Practical Implications for Users: You don’t need to know GAN details to use them, but understanding the basic concept helps you recognize what GAN-based tools do well. They excel at:
- Capturing stylistic essence of genres
- Generating novel but aesthetically appropriate combinations
- Creating diversity within consistent style
- Producing musically interesting surprises
They struggle with:
- Extreme novelty (radically new styles)
- Very long-form structure without repetition
- Precise control over specific elements
- Guaranteed adherence to music theory rules
When using GAN-based platforms (many commercial platforms use GAN architectures or hybrid approaches), generate multiple outputs and select the best. GANs produce variation by design—some generations will be better than others. This isn’t a bug; it’s a feature encouraging exploration of creative space.
We find GAN-generated music often has interesting happy accidents—unexpected but musically effective moments that human composers might not have considered. These moments are worth noting and potentially incorporating into your own compositions, even if you don’t use the AI-generated track directly.
The future of music GANs is promising. As architectures improve and training datasets expand, we expect GANs to handle increasingly sophisticated musical tasks while maintaining the creative unpredictability that makes them valuable for artistic applications. The competitive dynamic at their core seems particularly well-suited to creative domains where the goal isn’t following rules perfectly but creating aesthetically pleasing results that surprise and engage.
AI Music Generation: Comparing Rule-Based vs. AI-Driven Approaches
AI Music Generation: Comparing Rule-Based vs. AI-Driven Approaches clarifies a fundamental distinction in how algorithmic music creation works. Understanding this difference helps you choose the right tools and set appropriate expectations for what each approach delivers.
Rule-Based Music Generation operates on explicitly programmed musical rules. A human programmer writes code saying, “In major keys, vi chords typically follow I chords”, “Melodies should stay within vocal range”, “Chord changes usually happen on strong beats,” etc. The system generates music by following these rules, potentially with randomness within rule-constrained choices.
Early algorithmic composition used exclusively rule-based approaches. Mozart’s Musikalisches Würfelspiel (Musical Dice Game) from 1787 was rule-based—roll dice to select pre-composed measures, following rules about how measures connect. Modern rule-based systems are vastly more sophisticated but operate on the same principle: explicit rules guiding generation.
AI-Driven (Machine Learning) Approaches don’t receive explicit rules. Instead, they analyze thousands or millions of songs, learning patterns and relationships directly from examples. The system discovers “rules” itself—which chord progressions work, how melodies flow, what instruments combine effectively—by observing music rather than being told.
This distinction creates profound differences in strengths, weaknesses, and appropriate applications.
Rule-Based Strengths:
- Predictability: Output reliably follows rules, guaranteeing certain qualities
- Transparency: You understand exactly why the system made choices
- Precision Control: Detailed control over every aspect of generation
- Efficiency: Generally faster and less computationally intensive
- Music Theory Compliance: Can guarantee proper voice leading, harmonic function, etc.
- No Training Data Needed: Doesn’t require large datasets or copyright concerns
Rule-Based Weaknesses:
- Limited Creativity: Only as creative as the programmed rules allow
- Difficulty Capturing Nuance: Subtle stylistic elements resist explicit rule formulation
- Brittle: Small rule changes can break entire system
- Labor Intensive: Requires extensive expert knowledge to program effectively
- Stylistic Limitations: Each style requires separate rule set
AI-Driven Strengths:
- Style Capture: Learns subtle characteristics of genres without explicit programming
- Flexibility: Single system can learn multiple diverse styles
- Sophistication: Captures patterns too complex for explicit rules
- Surprise and Novelty: Can generate unexpected but appropriate combinations
- Continuous Improvement: Performance improves with more data and training
AI-Driven Weaknesses:
- Unpredictability: Can’t guarantee specific theoretical correctness
- Black Box: Difficult to understand why it made choices
- Data Dependency: Requires large training datasets with copyright implications
- Computational Intensity: Training requires significant computing resources
- Potential for Errors: May generate music theory mistakes or stylistic inconsistencies
- Bias: Reflects biases in training data
Hybrid Approaches: Most modern practical systems use hybrid approaches combining both methodologies. The AI generates creative material, then rule-based systems clean up theory errors. Or rule-based systems generate basic structure, then AI adds stylistic details. This combines predictable reliability with creative sophistication.
We’ve seen this in platforms like AIVA, which uses AI for creative generation but applies rules ensuring proper orchestration balance and avoiding music theory problems. The result sounds creative and natural (AI benefit) while maintaining technical correctness (rule-based benefit).
When to Prefer Rule-Based:
- Educational applications where understanding the generation process matters
- Applications requiring guaranteed music theory correctness
- Generating music for small, specific niches without AI training data
- When transparency and explainability are crucial
- Projects with limited computational resources
- Applications where licensing AI training data is problematic
When to Prefer AI-Driven:
- Capturing complex, subtle stylistic elements
- Generating diverse music across many genres
- Creative applications where surprise and novelty are desirable
- Applications where human-like musicality matters more than theoretical perfection
- Projects with access to substantial computing and training data
- When generating music similar to existing styles
Philosophical Implications: This comparison raises interesting questions about creativity. Rule-based systems follow explicit human-programmed instructions—they’re essentially elaborate tools executing composer intent. AI systems learn patterns from examples and generate novel combinations—they exhibit a form of autonomy and creativity, though still bounded by training data.
Some argue rule-based composition is more “honest”—the human explicitly programs every decision. Others argue AI-driven composition is more “creative”—the system discovers patterns and generates novel combinations without explicit instruction. We think both perspectives have merit, and the choice depends on your goals and values.
For practical music creation, we recommend starting with AI-driven platforms for their ease of use and impressive results, then exploring rule-based or hybrid systems if you need more control or want to understand generation mechanics deeper. Many creators use both approaches—AI for creative ideation and variation generation and rule-based systems for structured tasks like accompaniment or pedagogical applications.
The future likely involves increasingly sophisticated hybrid approaches that combine AI’s creative pattern recognition with rule-based systems’ reliability and controllability. This gives us the best of both worlds—creative, natural-sounding music that maintains technical quality and responds to precise creative direction.
AI Music Generation: The Impact on Independent Artists
AI Music Generation: The Impact on Independent Artists is a topic we approach with both optimism and honest acknowledgment of challenges. As independent artists ourselves, we’ve experienced how this technology simultaneously empowers and complicates the indie music landscape. The impact is nuanced, varying dramatically based on how artists engage with the technology.
Empowerment Through Accessibility: The most obvious benefit is democratized production. Recording quality music historically required studio access, professional equipment, and expensive engineering—barriers that excluded talented artists without financial resources. AI generation removes many of these barriers entirely. An indie artist can now:
- Generate professional backing tracks without hiring session musicians
- Create full production-quality arrangements from simple demos
- Produce hours of content for much less than traditional methods
- Experiment with sounds and styles previously requiring specialized knowledge
- Overcome creative blocks by generating inspiration quickly
We’ve witnessed this empowerment directly. One indie singer-songwriter we know uses AI to generate instrumentals, then records her vocals and guitar over them. Her released music sounds professionally produced despite her modest budget. Without AI, she’d be limited to sparse acoustic recordings or prohibitively expensive studio sessions.
Creative Expansion: AI tools let independent artists explore territory beyond their technical capabilities. A solo electronic producer can experiment with orchestral arrangements. A hip-hop artist can try incorporating jazz instrumentation. A folk musician can create layered harmonies without hiring backup singers. This expands creative possibility space dramatically.
The key is viewing AI as expanding your capabilities rather than replacing skills you should develop. Learn fundamentals—music theory, your primary instrument, and arrangement basics—but use AI to explore beyond those fundamentals and accelerate the journey from idea to finished product.
Business Model Challenges: However, we must acknowledge that AI music generation creates real challenges for independent artists:
Content Flood: Spotify, YouTube, and other platforms are being flooded with AI-generated content. Some estimates suggest millions of AI-generated tracks are uploaded monthly. This creates an overwhelming signal-to-noise problem, making discovery harder for all artists, including those creating genuinely original human-made music.
Streaming Economics Pressure: If algorithms can generate infinite “background music” at near-zero cost, what happens to artists who make their living creating functional music—study music, chill beats, and ambient soundscapes? The economic foundation for these genres is being disrupted. Artists must differentiate through exceptional quality, human connection, or shifting toward music that emphasizes the irreplaceable human elements AI can’t match.
Perception Questions: As AI-generated music becomes common, listeners may become skeptical about music’s authenticity. “Is this human-made or AI?” becomes a question artists must address. Full transparency helps—clearly communicating your creative process and human involvement builds trust.
Finding Competitive Advantage: Independent artists asking “How do I compete with AI?” are framing the question wrong. The better question: “How do I use AI as a tool while emphasizing what makes me irreplaceable?” Here’s what AI can’t provide:
Lived Experience and Authenticity: Songs about your actual life, emotions, and perspectives carry authenticity AI cannot replicate. Personal storytelling, especially combined with performance that expresses that story, creates connection AI lacks.
Cultural Context and Community: Music emerging from specific communities and cultural contexts carries meaning beyond its sonic properties. Being genuinely part of a scene, culture, or movement gives your music context that matters to audiences within those communities.
Performance and Presence: Live performance remains distinctly human. The energy, improvisation, connection with the audience, and physical presence create experiences AI cannot replace. Invest in live performance skills as part of your artistic development.
Unique Vision and Curation: Even if using AI for generation, your curatorial choices—selecting from hundreds of AI generations, editing and refining, and deciding what serves your artistic vision—reflect your unique aesthetic. This curation is artistry.
Transparency and Connection: Being open about your creative process, including AI use, builds audience connection. People appreciate understanding how music they love was made, including when technology plays a role.
Practical Strategies for Indies:
- Use AI as production tool but emphasize your human contribution prominently
- Focus on genres where human elements (vocals, lyrics, performance) are central
- Develop distinctive sonic signatures that aren’t easily replicated
- Build direct relationships with fans who value your specific artistic vision
- Be transparent about AI use while emphasizing your creative direction and curation
- Invest in live performance and visual elements that AI can’t replicate
- Focus on quality over quantity—a few exceptional human-curated tracks beat dozens of generic AI generations
Community and Collective Response: Independent artist communities are developing responses to AI disruption. Some platforms and labels specifically promote “100% human-made” music. Artist collectives share strategies for ethical AI use. Discussions about fair licensing and compensation structures are ongoing.
We believe the independent artists who will thrive are those who embrace technology as a tool while doubling down on distinctly human elements—authentic storytelling, community connection, live performance, and unique vision. AI changes the landscape but doesn’t eliminate the human hunger for genuine artistic expression and connection. Artists who can combine technological leverage with irreplaceable humanity will find their audiences.
AI Music Generation: Creating Music for Virtual Reality Experiences
AI Music Generation: Creating Music for Virtual Reality Experiences explores one of the most exciting applications where AI’s capabilities align perfectly with medium requirements. VR needs adaptive, responsive, infinite music that reacts to user actions—precisely what AI generation excels at providing.
Traditional approaches to VR music faced fundamental limitations. Pre-composed soundtracks couldn’t adapt to user behavior dynamically. Interactive music systems existed but required extensive manual creation of variations, layers, and transitions. AI generation solves these problems elegantly, creating music that responds fluidly to the unpredictable nature of VR exploration.
The Unique Demands of VR Music:
VR experiences are fundamentally nonlinear. Unlike films or games with defined paths, VR lets users explore environments at their own pace, spending varying amounts of time in different areas and approaching objectives from multiple directions. Music must adapt to this unpredictability without breaks, awkward transitions, or repetition that breaks immersion.
Additionally, VR is intensely immersive in ways that demand more sophisticated audio. Users feel more physically present in VR spaces than traditional media. Music that sounds generic or inappropriate breaks this presence immediately. The audio must feel genuinely part of the environment, not imposed from outside.
How AI Generation Addresses VR Needs:
Infinite Variation: AI can generate endless musical variations within a consistent style, preventing repetition even in extended VR sessions. A user exploring a virtual forest for 30 minutes never hears the same melody twice, yet the music maintains a consistent peaceful, natural character.
Real-Time Adaptation: Advanced systems generate music responding to user actions immediately. Approaching a mysterious structure? Music gradually adds tension. Discovering a beautiful vista? Music opens up with wonder. Combat begins? Rhythm and intensity increase instantly. AI generation makes this adaptation smooth and musically coherent.
Environmental Consistency: AI trained on specific moods or genres generates endless content that maintains environmental character. A cyberpunk city environment can have constantly evolving electronic music that always sounds appropriately cyberpunk without repetition or abrupt changes.
Spatial Audio Integration: AI-generated music can be spatially positioned in VR environments—different instruments coming from different directions, music changing as users move through space. This creates unprecedented immersion where music feels like it exists within the VR world rather than playing “over” the experience.
Practical Implementation Approaches:
Layered Generation: Generate multiple musical layers (ambient background, melodic elements, and rhythmic components) that combine or separate based on user actions. In exploration mode, only ambient layers play. Approaching points of interest adds melodic elements. Intense moments add rhythmic drive. Each layer generates continuously, so transitions happen naturally.
State-Based Generation: Define VR experience states (exploration, contemplation, action, tension, resolution) with associated musical characteristics. As users transition between states, AI generates appropriate music for each state with smooth interpolations between them. The generation happens in real-time, ensuring infinite content without repetition.
Generative Soundscaping: Combine AI music generation with generative sound effects, creating complete sonic environments. Footsteps, environmental ambiance, and musical elements all respond to user position and actions, creating cohesive audio worlds that enhance presence.
User-Influenced Generation: Some experimental VR experiences let users influence music generation through their movements or choices. Hand gestures might affect instrumentation, movement speed influences tempo, and gaze direction shifts harmonic content. This transforms users from passive listeners to active participants in musical creation.
Case Examples We’ve Explored:
Meditation VR: We worked on a VR meditation space where AI generates evolving ambient soundscapes. As users progress through meditation sessions, music subtly evolves—starting complex and gradually simplifying, becoming more spacious. Each session generates unique music, but all sessions share the calming, supportive qualities needed for meditation. The AI ensures no two meditation sessions sound identical, maintaining novelty for regular users.
Fantasy RPG World: A VR fantasy game using AIVA-generated orchestral music that responds to gameplay. Different regions have distinct musical themes, but within each region, AI generates endless variations. Combat triggers more intense arrangements of regional themes, while exploration uses gentler variations. Players never hear exact repetition even in 100+ hour playthroughs.
Abstract Art Experience: A VR gallery where artwork generates corresponding music. Users approach abstract paintings, and AI analyzes colors, shapes, and composition, generating music reflecting the artwork’s visual qualities. Bright colors trigger major keys and higher frequencies; dark colors create minor keys and lower-frequency music. Each artwork has a unique, generatively created soundtrack that exists only while viewing it.
Challenges and Solutions:
Latency: Generation must happen quickly enough to respond to user actions without noticeable delay. Solutions include pre-generating small buffers of musical material and using computationally efficient generation algorithms optimized for real-time use.
Continuity: Transitions between musical states must be smooth and musically logical. Solutions include generating transition segments specifically designed to bridge states and using techniques like cross-fading and harmonic matching.
Computational Load: VR already demands significant computing resources for graphics. Adding real-time music generation must not compromise performance. Solutions include offloading generation to cloud servers, optimizing algorithms, or using hybrid approaches with pre-generated elements augmented by real-time AI variation.
Future Possibilities:
We’re excited about multiplayer VR experiences where AI generates music responding to multiple users simultaneously, creating soundscapes reflecting collective actions and emotional states. Imagine a VR concert where the music adapts to audience reactions in real-time, or collaborative VR art spaces where multiple users’ creative actions collectively influence the generated soundtrack.
The convergence of AI music generation and VR creates opportunities for musical experiences impossible in traditional media. Music becomes not just accompaniment but an integral, responsive part of the world itself—as present and adaptive as the virtual environment. This elevates VR immersion while creating entirely new categories of musical experience that blur boundaries between composition, performance, and interactive art.
AI Music Generation: Exploring the Use of Symbolic Music Representation
AI Music Generation: Exploring the Use of Symbolic Music Representation delves into a technical topic that significantly affects how AI generates music. Understanding this helps explain why some AI systems excel at certain tasks while struggling with others and can inform which tools you choose for specific applications.
What is Symbolic Representation? Music exists in multiple forms: as sound waves we hear, as sheet music notation, as MIDI data, or as text descriptions. Symbolic representation refers to encoding music in abstract notation rather than as actual audio. MIDI is the most common symbolic format—it doesn’t contain actual sounds but instructions: “Play Middle C at velocity 64 for a quarter note duration.”
Think of the difference like recipes versus prepared meals. A recipe (symbolic) contains instructions for creating food but isn’t edible itself. A prepared meal (audio) is the actual food. AI music generation can work with either symbolic instructions or direct audio generation, and this choice profoundly affects capabilities.
Advantages of Symbolic Representation:
Computational Efficiency: MIDI files are tiny—a complex orchestral piece might be 50 KB as MIDI versus 50 MB as audio. AI can process, analyze, and generate symbolic music much faster and with less computing power than audio. This makes symbolic generation practical on regular computers rather than requiring specialized hardware.
Precise Editing: When music is symbolic, you can modify exact notes, timing, velocities, and other parameters with perfect precision. You can’t easily “edit” a recording to change one note in a chord without affecting timbre, but you can instantly edit that note in MIDI.
Music Theory Alignment: Symbolic representation naturally aligns with music theory concepts—notes, chords, scales, keys, and time signatures. This makes it easier to apply theory rules and constraints during generation. AI working symbolically can more easily ensure proper voice leading, harmonic progressions, and structural coherence.
Flexible Instrumentation: A symbolic composition can be played back with any instrument sounds. The same MIDI file can sound like a piano, guitar, orchestra, or synthesizers. This flexibility is valuable for experimentation and production.
Disadvantages of Symbolic Representation:
Limited Expressiveness: MIDI captures note events but not the infinite subtlety of real performances—breath noise in flute playing, string resonances in guitars, and the way a piano hammer hits strings. These timbral qualities are crucial to music’s emotional impact but aren’t present in symbolic form.
Genre Limitations: Some genres rely heavily on timbral manipulation and audio production techniques that symbolic representation can’t capture. Electronic music, in particular, often centers on sound design and processing that doesn’t translate to MIDI.
Less “Human” Sound: Music generated symbolically and then synthesized often sounds more mechanical than music generated as audio directly. The subtle timing imperfections, dynamic variations, and timbral shifts that make performances feel human are difficult to encode symbolically.
Real-World Performance Loss: A jazz piano performance includes not just which notes are played but also how they’re approached, released, and how the sustain pedal is used. MIDI captures some of this but loses much of the nuance.
Audio Generation Approaches:
Contrast symbolic generation with direct audio generation (sometimes called “audio-native” or “waveform generation”). Systems like MusicLM, AudioLM, and recent versions of Suno generate audio directly without intermediate symbolic representation. They learn relationships between audio features—frequencies, amplitudes, and timbres—creating sound directly.
Advantages of Audio Generation:
- Captures full timbral richness and expression
- Better for genres relying on production and sound design
- Can include vocals and complex acoustic instruments realistically
- Produces more “human-sounding” results
Disadvantages of Audio Generation:
- Computationally intensive, requiring powerful hardware
- Harder to edit precisely after generation
- More prone to artifacts and quality issues
- Black box—harder to understand or control specific musical elements
Hybrid Approaches:
Many modern systems use hybrid approaches. Generate music symbolically for structure and notes, then use AI audio generation to render it with realistic instrument sounds. Or generate audio, but use symbolic representation for intermediate processing and editing. AIVA uses this approach—it generates MIDI (symbolic), which users can edit, then renders with high-quality sample libraries.
Practical Implications for Users:
When choosing platforms, consider:
- Need precise editing? Choose symbolic-capable systems
- Want quick iteration? Symbolic is faster
- Need realistic vocals or complex timbres? Choose audio generation
- Working in electronic genres with heavy production? Audio generation likely better
- Orchestral or structured composition? Symbolic representations work excellently
- Want to import into DAWs for further work? Symbolic MIDI export is valuable
Understanding symbolic representation also helps you work more effectively with AI tools. When using symbolic systems, thinking in terms of melody, harmony, and rhythm makes sense. When using audio generation, thinking in terms of overall sound, timbre, and production aesthetic is more appropriate.
The Future: Best of Both Worlds:
We’re moving toward systems that seamlessly integrate symbolic and audio approaches. Generate music symbolically for structure and editability, render it as realistic audio for listening, and allow editing in either domain. Some systems let you modify MIDI notes (symbolic) and have those changes reflected in audio immediately, or adjust audio characteristics (like instrument timbre) and have those changes back-propagate to symbolic representation.
This convergence will give us the precision and efficiency of symbolic representation with the expressiveness and realism of audio generation—truly the best of both worlds for AI music creation.
AI Music Generation: Generating Sound Effects and Foley Art
AI Music Generation: Generating Sound Effects and Foley Art extends beyond music into the broader world of audio production. While we’ve focused primarily on music, the same technologies generate sound effects, ambient sounds, and foley—with significant implications for film, game, and multimedia production.
Foley art—creating everyday sound effects synchronized to visual media—has traditionally been labor-intensive, specialized work. Foley artists perform actions like walking, closing doors, or rustling clothing while watching video, recording sounds that match on-screen actions. It’s skilled work requiring precise timing, creative problem-solving, and extensive sound libraries. AI is beginning to augment and sometimes replace parts of this process.
Sound Effect Generation:
Current AI systems can generate surprisingly convincing sound effects from text descriptions. We’ve experimented with platforms that create:
- Environmental sounds: rain, wind, forest ambiance, city noise
- Action sounds: doors closing, footsteps on various surfaces, glass breaking
- Mechanical sounds: car engines, computer beeps, machinery
- Abstract sounds: swooshes, impacts, transitions for video editing
The process is similar to AI music generation. You describe what you want—”heavy footsteps on gravel, steady pace, with slight echo”—and the system generates appropriate audio. Quality varies significantly based on sound complexity and how well-represented that sound is in training data. Common sounds like footsteps or doors work well; unusual or specific sounds are less consistent.
Applications We’ve Explored:
Video Editing: Content creators use AI-generated sound effects for YouTube videos, vlogs, and presentations. Rather than searching sound effect libraries for hours, describe what you need and generate it. This dramatically accelerates production workflow, especially for creators producing high volumes of content.
Game Audio: Indie game developers use AI to generate footstep variations for different surfaces, ambient environmental sounds, and interface audio feedback. One developer we interviewed generated 50 variations of footsteps—wet grass, dry leaves, metal grating, wooden floors—in an afternoon. Hiring a sound designer or recording these personally would have taken weeks and a significant budget.
Podcast Production: Podcasters generate transition sounds, intro/outro elements, and ambient backgrounds matching their content themes. A true crime podcast might have eerie atmospheric sounds; a comedy podcast might have upbeat, playful elements. AI generation allows customization rather than using generic stock sounds everyone recognizes.
Film and Animation: Independent filmmakers use AI for sound effects and ambient tracks that would traditionally require foley artists. While major productions still employ traditional foley for quality and precision, independent films on tight budgets find AI generation enables professional audio that wasn’t previously accessible.
Strengths and Limitations:
AI excels at:
- Simple, common sound effects with clear acoustic characteristics
- Ambient environmental sounds with natural variation
- Electronic and synthetic sounds for UI and transitions
- Generating variations of similar sounds efficiently
- Creating abstract sounds that don’t require realism
AI struggles with:
- Extremely precise synchronization to visual timing
- Complex layered sounds with multiple interacting elements
- Sounds requiring perfect realism for discerning audiences
- Unusual sounds with limited training data
- Matching perspective and acoustics perfectly to visual environments
Workflow Integration:
Our recommended workflow for AI sound effects:
- Generate multiple variations of each needed sound (10-20 options)
- Listen critically and select best matches
- Import to audio editing software for timing adjustments
- Layer multiple AI generations for richer, more complex sounds
- Process with EQ, reverb, and effects to integrate into your project
- Consider mixing AI-generated and traditionally recorded sounds
This hybrid approach gives you AI’s speed and cost-effectiveness while maintaining quality through human curation and processing.
Ambient Soundscape Creation:
AI particularly excels at generating rich environmental soundscapes—the subtle layers of background audio that create a sense of place. A forest scene might need:
- Wind through trees at various distances
- Bird calls (multiple species)
- Rustling leaves underfoot
- Distant animal sounds
- Insect buzzing
- Stream or rain sounds
Traditionally, layering these elements from sound libraries took hours and resulted in recognizable sounds many audiences had heard in other productions. AI generates unique combinations, creating distinctive sonic environments. We created a 10-minute alien planet soundscape—completely inhuman environmental audio—that would have been nearly impossible with traditional libraries.
Ethical and Practical Considerations:
Like AI music generation, sound effect generation raises questions about sound designers’ livelihoods and the copyright of training audio. Some platforms train exclusively on properly licensed or original recordings; others operate in legal gray areas.
Our recommendations:
- For professional high-budget productions, use AI to accelerate workflow but maintain human sound designers for final quality
- For independent and budget-constrained projects, AI makes professional audio accessible
- Be transparent about AI use in credits
- Support platforms using ethically sourced training audio
- Don’t completely replace learning about sound design—understanding good audio helps you generate and select better AI outputs
Future Possibilities:
We anticipate “video-to-sound” systems that watch video and automatically generate synchronized sound effects. Early experiments exist—AI analyzes visual motion and generates corresponding audio. Imagine uploading your silent video footage and receiving fully sound-designed audio matching all on-screen actions. We’re maybe 3-5 years from this being practical for production use.
Another exciting direction: parametric sound generation, where you adjust controls like “wetness”, “brightness” , “roughness” and sounds morph accordingly. This would give sound designers unprecedented control over generated audio, tweaking sounds to fit needs perfectly rather than accepting what random generation produces.
The integration of AI sound generation with music generation will create complete audio environments from single prompts—”Create 2-minute audio for scary hallway scene: eerie ambient music, distant footsteps, creaking doors, low tension drones.” Both music and effects were generated cohesively, properly balanced, and spatially positioned. For multimedia creators, this represents a revolution in audio post-production efficiency.
AI Music Generation: Overcoming the Bias in Training Data
AI Music Generation: Overcoming the Bias in Training Data addresses a critical issue affecting quality, fairness, and cultural representation in AI-generated music. As we’ve worked extensively with these systems, we’ve repeatedly encountered biases reflecting the limitations and imbalances in the datasets used for training. Understanding and addressing these biases is crucial for responsible AI music creation.
What is Training Data Bias?
AI systems learn only from the data they’re trained on. If training data over-represents certain genres, cultures, or musical approaches while under-representing others, the AI will reflect those imbalances. It’s not a technical flaw—it’s a data problem with social, cultural, and artistic implications.
Types of Bias We’ve Observed:
Genre Bias: Most commercial AI music systems are disproportionately trained on Western popular music—pop, rock, electronic, hip-hop, and country. This means generating excellent pop music is easy, but creating authentic traditional Japanese koto music, West African drumming, or Indian classical ragas is difficult because those traditions are underrepresented in training data.
We tested this systematically: generating music from 20 different global traditions. Western genres produced consistently high-quality, stylistically accurate results. Non-Western traditions produced output that sounded superficially correct but lacked authentic details someone from those traditions would immediately recognize as wrong.
Cultural Bias: Related to genre bias but broader— AI trained predominantly on Western music understands Western harmonic systems, rhythmic structures, and formal conventions. When asked to generate music from traditions using different tuning systems, modal frameworks, or rhythmic concepts, results are often Western music with exotic instruments rather than authentic cultural music.
This isn’t just an aesthetic issue—it’s a respect and representation issue. When AI produces culturally inauthentic music, it risks perpetuating stereotypes and marginalizing musical traditions that are already underrepresented in mainstream music technology.
Era Bias: Training data often emphasizes recent music over historical traditions. Generating contemporary pop is easier than authentic 18th-century baroque music because modern music is more represented in accessible digital form. This creates a recency bias where older traditions become progressively harder to authentically recreate.
Gender and Demographic Bias: In vocal music, biases exist around gender, age, and other demographic characteristics. Some systems are better at generating certain vocal types because those voices are more common in training data. This reflects existing biases in the music industry, where certain voices have been historically privileged.
Complexity Bias: Training data tends to include more polished, professionally produced music than amateur or experimental work. This creates bias toward conventional, commercially successful musical approaches. Truly experimental or avant-garde music is underrepresented, making generating genuinely innovative music difficult.
Strategies for Mitigating Bias:
Diversifying Training Datasets: The most direct solution is ensuring training data represents global musical diversity proportionally. Projects like Open Music Data are working toward comprehensive, culturally diverse music datasets. This requires collaboration with musicians and scholars from diverse traditions to ensure authentic representation.
Specialized Models: Rather than one universal model, train specialized models on specific traditions—one for jazz, another for Indian classical, and another for traditional Chinese music. These focused models capture tradition-specific subtleties better than generalized models. AIVA offers some genre-specific models following this approach.
Cultural Consultation: When developing AI systems for specific traditions, involve practitioners and scholars from those traditions throughout development. They can identify authentic characteristics, flag problematic outputs, and ensure respectful representation.
Transparent Data Sourcing: Platforms should disclose training data sources, allowing users to understand biases and limitations. If a platform says “trained on 100,000 songs from Western popular music traditions,” users know what to expect and can adjust expectations for generating other styles.
Augmentation and Synthetic Data: For underrepresented traditions, generate synthetic training examples following authentic musical rules. While not perfect, this supplements limited real-world data. Combine with transfer learning—pre-train on abundant data from similar traditions, then fine-tune on limited authentic examples.
User Education: Teach users about bias and set appropriate expectations. Make clear that generating authentic music from underrepresented traditions may require additional human expertise to refine results.
Practical Implications for Creators:
When using AI music generation:
- Be aware that some styles will be better represented than others
- For culturally specific music, involve people from that culture in evaluating authenticity
- Don’t assume AI generates authentic cultural music without verification
- Consider supplementing AI generation with human performance from traditionally trained musicians
- Be transparent about limitations when sharing AI-generated cultural music
- Support platforms working toward more diverse, equitably represented training data
Personal Experience:
We attempted generating music inspired by Moroccan gnawa traditions—a spiritual musical tradition with specific rhythmic patterns, instrument combinations, and melodic characteristics. The AI-generated result sounded vaguely Middle Eastern but lacked the distinctive krakebs (metal castanets), the specific rhythmic cycles, and the spiritual intensity characteristic of authentic gnawa. Using it without extensive human refinement and cultural consultation would have been disrespectful.
Instead, we used the AI generation as a starting point, then collaborated with a musician familiar with gnawa traditions to refine the output, add authentic instruments, and correct musical elements. The final result respectfully incorporated inspiration from the tradition without claiming to be authentic gnawa music.
The Path Forward:
Overcoming training data bias requires sustained effort from multiple stakeholders:
- Technology companies must invest in diverse dataset collection and model development
- Musicians and scholars from underrepresented traditions must be involved and compensated for their expertise
- Users must educated themselves about limitations and use technology responsibly
- Funding organizations should support projects diversifying music technology training data
- Academic researchers should prioritize equitable representation in music AI research
The goal isn’t just technical improvement—it’s ensuring AI music technology respects and represents global musical diversity equitably, empowering musicians from all traditions rather than marginalizing those whose music is underrepresented in training data. This is both an ethical imperative and an opportunity to create more creatively rich AI systems that truly serve global creativity.
AI Music Generation: The Role of Human Feedback in AI Training
AI Music Generation: The Role of Human Feedback in AI Training explores how systems improve through interaction with human evaluators—a process crucial for creating AI that generates music people actually want to hear. This feedback loop bridges the gap between technical capability and aesthetic quality, and understanding it helps you appreciate how these systems develop and how you can contribute to their improvement.
What is Human Feedback in AI Training?
Initially, AI learns from existing music in datasets, identifying patterns and relationships through purely computational analysis. However, what makes music “good” is subjective and context-dependent—qualities that pure statistical learning struggles with. Human feedback provides the evaluative dimension: “This generation is excellent,” “This one is mediocre,” “This one is terrible.” The AI then learns to generate more music similar to what humans rate highly.
The technical term is Reinforcement Learning from Human Feedback (RLHF). The AI generates music, humans evaluate it, and the system adjusts its generation strategy to produce outputs that receive positive feedback more frequently. Over many iterations, this steers the AI toward generating aesthetically pleasing music rather than just technically pattern-matching.
Types of Human Feedback:
Explicit Ratings: Users directly rate AI generations on scales like 1-5 stars or thumbs up/down. Many platforms incorporate this—when you use Suno or AIVA, your interactions provide feedback, helping improve the system. Liking a generation tells the AI, “Make more like this.” Skipping or deleting tells it, “This wasn’t successful.”
Implicit Behavioral Feedback: Even without explicit ratings, your behavior provides signals. How long you listen to a generation before skipping indicates quality. Which generations you download or use in projects signals preference. Whether you generate variations of a particular output suggests you found it promising. This passive feedback aggregates across millions of users, revealing patterns about what works.
Comparative Feedback: Rather than rating individual generations, humans compare pairs: “Which of these is better?” This comparative approach is sometimes easier for evaluators and provides clearer learning signals. The AI learns relative preferences—not just that something is good, but that it’s better than alternatives.
Expert Curation: Professional musicians and producers evaluate AI outputs, providing high-quality feedback from trained perspectives. This expert feedback refines the AI’s understanding of musical quality, going beyond popular preference to include technical excellence.
Adversarial Feedback: In GAN architectures, the discriminator network provides constant feedback to the generator about whether outputs are realistic. This is automated human feedback—the discriminator learned from human-created music and now provides feedback mimicking human evaluation.
The Feedback Loop in Practice:
Here’s how human feedback shapes AI music generation development:
- Initial Training: AI trains on large music datasets, learning basic patterns and structures
- Generation: AI generates new music based on learned patterns
- Human Evaluation: People listen and evaluate these generations
- Analysis: Developers analyze feedback patterns—what do highly rated generations have in common? What do poorly rated ones share?
- Refinement: The AI’s generation strategy adjusts to favor characteristics of highly-rated outputs
- Iteration: Process repeats continuously, progressively refining quality
This cycle happens continuously in commercial platforms. Every time you use these systems, your interactions potentially contribute to improving them for everyone.
Challenges in Human Feedback:
Subjectivity: Musical taste is deeply personal. One person’s favorite generation is another’s least preferred. Aggregating across many users helps identify broader patterns, but individual feedback can be noisy and contradictory.
Cultural Bias: If feedback comes predominantly from one cultural context, the AI learns to optimize for that culture’s musical preferences. This potentially reinforces existing biases rather than creating culturally neutral systems. Diverse evaluator pools are essential.
Context Dependence: Music quality depends on context. A generation perfect for meditation might be terrible for a party. Without context about intended use, feedback can be misleading. Some platforms now include context in feedback collection: “How well does this fit your stated purpose?”
Expertise vs. Popularity: Should systems optimize for popular preference or expert evaluation? Music that’s technically excellent might not be broadly popular. Music that’s popular might not meet professional standards. Different platforms prioritize differently—some optimize for widespread appeal, others for professional quality.
Feedback Fatigue: Providing detailed feedback is effort. Most users won’t rate every generation carefully. This creates reliance on implicit behavioral feedback, which is noisier and less informative than explicit evaluation.
Your Role in Improving AI Music:
As users, we actively contribute to these systems’ improvement:
- Rate generations honestly when platforms request feedback
- Provide specific feedback when possible—not just “good” or “bad”, but why
- Report problematic outputs—technical glitches, inappropriate content, cultural inaccuracies
- Participate in beta testing and research studies if opportunities arise
- Share successful prompts and techniques with communities, helping collective understanding
Your individual feedback might seem insignificant, but aggregated across millions of users, it profoundly shapes these systems’ development trajectory. We’re collectively teaching AI what good music is.
Ethical Considerations:
Human feedback in AI training raises questions about representation. Whose aesthetic preferences should guide AI development? If feedback comes primarily from certain demographics, AI learns those preferences as universal. Ensuring diverse feedback populations is crucial for creating AI systems serving global musical diversity.
Additionally, feedback collection should respect privacy and obtain informed consent. Users should understand that their interactions may train AI systems and have the opportunity to opt out if desired.
Future Directions:
We anticipate more sophisticated feedback mechanisms:
- Explaining ratings: “Good melody but drums too prominent”
- Contextual feedback: Evaluating based on stated purpose and style goals
- Collaborative feedback: Groups evaluating together, discussing what works
- Long-term feedback: Rating how well generated music holds up over repeated listening
- Multidimensional feedback: Separately rating melody, harmony, rhythm, production, etc.
These richer feedback types will enable AI to learn a more nuanced understanding of musical quality, creating systems that generate not just technically proficient music but genuinely moving, engaging, culturally respectful compositions that serve diverse human needs and preferences.
AI Music Generation: Creating Interactive Music Installations
AI Music Generation: Creating Interactive Music Installations explores cutting-edge artistic applications where AI generates music responding to physical spaces, audience presence, and environmental factors. This represents one of the most creatively exciting frontiers we’ve encountered—music that exists not as fixed recordings but as ever-evolving generative systems embedded in physical and digital spaces.
Interactive music installations have existed for decades—early examples used simple sensors triggering prerecorded sounds or rule-based algorithmic systems. What AI brings is sophistication: music that responds intelligently to complex input, learns from interaction patterns, and generates original compositions rather than rearranging existing materials.
Types of Interactive Installations We’ve Explored:
Motion-Responsive Installations: Visitors’ movements through physical space control musical generation. Walk quickly, and the tempo increases. Move smoothly, and melodies flow legato. Sharp gestures create staccato punctuations. Multiple people in the space create layered musical complexity. The AI interprets motion patterns and generates appropriate musical responses in real time.
We collaborated on an installation in a gallery where visitors’ paths through the space left “trails” of music. Each person’s movement generated a unique melodic line that continued evolving after they left, creating a collective composition from all visitors’ contributions. The AI ensured these overlapping melodies remained harmonically coherent even as dozens of visitors created simultaneous musical layers.
Environmental Data Sonification: Real-world data—weather, air quality, social media activity, financial markets—transformed into music. The AI doesn’t just map data to pitch or volume but interprets it musically, creating compositions that express the data’s character. Rising temperatures might create ascending melodic phrases; fluctuating stock markets generate rhythmic instability.
One installation we developed for a public space generated music from local weather conditions. Sunny days produced bright major-key compositions, rainy days created contemplative minor-key pieces, and wind speed controlled tempo. The AI ensured 24/7 continuous music that was always unique yet always appropriate to current conditions.
Participatory Creation Spaces: Installations where audience members directly influence musical generation through touch, voice, or gesture. Imagine a wall of light-up panels—touching different panels triggers different musical parameters, and the AI weaves your inputs into coherent compositions. Multiple people can contribute simultaneously, creating collaborative improvisation between humans and AI.
Biometric-Responsive Music: Using sensors measuring heart rate, breathing, galvanic skin response, or brainwaves to generate music reflecting visitors’ physiological states. This creates deeply personal musical experiences—anxious visitors might hear calming music, while calm visitors receive gently stimulating compositions. The AI adapts generation strategies to individual autonomic nervous system states.
We experimented with a meditation space where EEG headbands measured brain activity, and AI generated soundscapes supporting meditative states. When users’ minds wandered (increased beta waves), music became slightly more engaging, gently guiding attention back. Deep meditation (increased theta waves) triggered more spacious, minimal compositions supporting that state.
Technical Implementation:
Creating interactive AI music installations requires integrating several components:
Sensing Systems: Cameras tracking movement, depth sensors mapping space usage, microphones capturing ambient sound, environmental sensors measuring temperature/light/etc., physiological sensors for biometric data, touch-sensitive surfaces for direct interaction.
AI Generation Engine: Running locally or in the cloud, receiving sensor data and generating music continuously. Must generate fast enough for real-time responsiveness—typically pre-generating short buffers of musical material that adapt to incoming data.
Spatial Audio Systems: Multiple speakers positioned throughout the space, creating three-dimensional sound fields. Different musical elements can be positioned spatially, and sound can move through the space following user movements or programmatic control.
Visual Components: Many installations combine audio with visuals. Projection-mapping, LED arrays, or screens display visualizations of the musical structure or sensor data, helping visitors understand how their interactions affect sound.
Control Algorithms: The logic determining how sensor input maps to musical parameters. This is crucial design work—simple direct mappings (movement speed = tempo) can feel obvious and boring, while sophisticated mappings create surprising, delightful interactions.
Design Considerations:
Understandability vs. Surprise: Installations need balance between being understandable (visitors can intuit how their actions affect music) and surprising (the system does unexpected interesting things). Too obvious is boring; too opaque is frustrating. We aim for clear causation with sophisticated elaboration—you see that your movement affects music, but the AI elaborates your input in musically interesting ways you wouldn’t predict exactly.
Musical Coherence: With multiple people interacting, maintaining musical coherence is challenging. The AI must integrate diverse inputs into unified compositions. We use harmonic constraints (all contributions use compatible keys) and rhythmic quantization (inputs snap to beat grid) while allowing melodic and timbral diversity.
Graceful Degradation: What happens when no one is present? Complete silence feels dead; continuous music regardless of presence makes interaction meaningless. We typically generate minimal ambient soundscapes when unattended, becoming more active with visitors. The AI creates smooth transitions between these states.
Accessibility: Installations should be accessible to people with various abilities. Multiple interaction modes (gesture, touch, voice) ensure different people can participate meaningfully. The AI should respond to both subtle and obvious inputs, accommodating various movement capabilities.
Case Study: “Harmonic Forest”
We designed an outdoor installation where artificial trees equipped with sensors generated music based on visitors’ presence and environmental conditions. Each tree had its own distinct musical voice (one emphasized percussion, another melodic content, another harmonic foundation). As visitors walked between trees, their proximity activated different trees’ contributions to the collective soundscape.
Wind moving tree branches created gentle melodic variations. Multiple visitors created richer, more complex harmonies. Temperature and humidity affected timbral qualities—hot dry days produced bright, crisp sounds; cool humid days created warmer, softer tones. The AI ensured all these elements cohered musically while maintaining the feeling that the forest itself was alive and musical.
The installation ran continuously for six months, generating unique music every moment without repetition. Visitors reported feeling personally connected to the space—their presence mattered, their movements contributed to something larger, and returning multiple times revealed the system’s depth and personality.
Future Possibilities:
We’re excited about installations that learn visitor preferences over time, generating music that evolves based on which interactions receive positive engagement. Installations networked across multiple physical locations, creating musical dialogues between distant spaces. AR-enhanced installations where visitors wearing AR glasses see visualizations of the musical structure overlaid on physical space.
The convergence of AI music generation, environmental sensing, and spatial audio creates possibilities for musical experiences that couldn’t exist in traditional formats—music that’s simultaneously deeply personal (responding to your presence and actions) and collective (incorporating everyone’s contributions), that exists in specific places and moments rather than as reproducible recordings, that blurs boundaries between composition, performance, and installation art. This is where music, technology, and space come together in genuinely new ways, and AI generation is the key enabling technology making it all possible.
Conclusion: Embracing AI as Your Creative Partner
We’ve explored AI music generation from countless angles—technical foundations, practical applications, creative possibilities, ethical considerations, and future directions. If you’ve made it this far, you have a comprehensive understanding of this transformative technology. Now comes the most important part: actually using it.
The central insight we hope you take away is this: AI music generation isn’t about replacing human creativity; it’s about amplifying it. The technology is a tool, powerful and sophisticated, but ultimately guided by human intention, taste, and vision. Your role as creator remains essential—you provide the purpose, the aesthetic direction, the cultural context, and the final judgment about what serves your artistic goals.
Start experimenting today. Choose a platform that fits your needs and budget. Generate your first compositions. They might not be perfect—ours certainly weren’t—but each generation teaches you something about how to communicate effectively with AI, what works musically, and where your creative interests lie. Document what you learn. Save successful prompts. Build your personal library of AI-generated material.
Be ethical and thoughtful in your use. Understand where your tools’ training data comes from. Respect cultural traditions and intellectual property. Be transparent about AI’s role in your work. Support platforms working toward fair compensation for artists and diverse representation in training data.
Most importantly, maintain your human creative voice. AI can generate infinite variations on existing styles, but only you can decide which variations serve your unique artistic vision. Only you bring lived experience, emotional authenticity, and intentional meaning to your music. Use AI to accelerate your creative workflow, break through blocks, and explore new territory, but never let it replace your artistic judgment and personal expression.
The future of music is collaborative—humans and AI working together, each contributing what they do best. This partnership promises to democratize music creation, making professional-quality composition accessible to millions who never thought they could make music. It promises to expand creative possibilities, letting artists explore sonic territories previously beyond reach. And it promises to create entirely new musical experiences—adaptive, personalized, interactive—that couldn’t exist before.
We’re at the beginning of this journey, not the end. The technology will continue improving, becoming more sophisticated, more accessible, and more integrated with how we create and experience music. Your early experimentation now positions you to take full advantage of these developments, developing skills and understanding that will remain valuable as the field evolves.
So don’t wait for the perfect moment or the perfect tool. Start creating today. Let AI amplify your creativity. Make music that couldn’t have existed without this partnership between human artistry and artificial intelligence. The future of music is being written right now, and you’re invited to be part of writing it.
Now go make something beautiful.
Author Bio
This comprehensive guide was created through the collaborative expertise of Alex Rivera and Abir Benali, combining Alex’s creative technologist perspective with Abir’s accessible, beginner-friendly approach to explaining AI tools.
Alex Rivera is a creative technologist passionate about helping non-technical users harness AI for content generation and creative expression. With a background in both technology and arts, Alex specializes in making complex tools approachable, inspiring, and fun for everyone—regardless of technical experience.
Abir Benali is a friendly technology writer dedicated to demystifying AI tools for everyday users. Abir’s clear, concise writing style and focus on practical, actionable instructions has helped thousands of people confidently explore AI technology in their creative and professional lives.
Together, we combine technical knowledge, creative experimentation, and a deep commitment to making AI accessible to all creators. Our goal isn’t just to explain how technology works, but to empower you to use it meaningfully in your own creative journey.